サードパーティーデータのインポート
CDB を使用すると、サードパーティ製システムからデータをインポートして、CDB ワークベンチアプリケーションでクリーニングやレポートを作成することができます。これは、Veeva EDC の症例のケースブックの外部に存在する症例データ (IRT システムからの症例に関するデータなど) をインポートするためのものです。
可用性: 臨床データベース (CDB) は CDB ライセンスを保有するお客様のみにご利用いただけます。詳細は Veeva のサービス担当者までお問い合わせください。
前提条件
CDB にデータをインポートする前に、組織で以下の作業を行う必要があります:
- スタディ、スタディ実施国、スタディ実施施設の作成。
- Veeva EDC スタジオで、ケースブック定義、完全なデザイン定義レコードのセット、スタディスケジュールの作成と公開。詳細はこちらを参照してください
- 症例ごとにケースブックレコードを作成
CDMS リードデータマネージャ標準試験ロールを持つユーザは、デフォルトで下記のアクションを実行することができます。組織がカスタムロールを使用する場合、そのロールには以下の権限を付与することが必要です:
| タイプ | 権限ラベル | 制御 |
|---|---|---|
| 標準タブ | ワークベンチタブ | ワークベンチタブからデータワークベンチアプリケーションにアクセスする権限 |
| 機能権限 | インポートの表示 | インポートページにアクセスする権限 |
| 機能権限 | API アクセス | Vault EDC API にアクセスし使用する権限(この許可は CDB 使用時にも必要です)。 |
| 機能権限 | インポートの承認 | 設定変更を含むインポートパッケージを承認または却下する権限 |
| 機能権限 | インポートパッケージのダウンロード | インポートパッケージをダウンロードする権限 |
| 機能権限 | 3PDパッケージのアップロード | CDBパッケージローダを介してデータをインポートする権限。 |
インポート用データの準備
データは、一連のCSVファイルとしてVaultのFTPサーバにインポートするか、CDBユーザインタフェース内のCDBパッケージローダを使用してアップロードできます。
データをインポートするには、まず臨床データが記載された CSV ファイルに加え、データと CDB の処理方法が記述されたマニフェストファイル (.json) を作成する必要があります。次に、これらのファイルをすべて含むZIPパッケージ (.zip) を作成して、CDBにインポートします。
マニフェストビルダー: CDB には、ファイル作成を容易にするための CDB マニフェストビルダーが同梱されています。CDB マニフェストビルダーは、すべてのマニフェストファイルの設定に関する選択肢をユーザフレンドリーなインターフェイスでガイドする、ステップバイステップ式のウィザードです。CDB マニフェストビルダーでは、CDB によってあらゆるインポートに関する選択肢が提示されるため、設定に際して JSON に対する理解は不要です。
CSV データ
スタディのデータコレクションフォームごとに、EDC から独立した CSV を作成します。CSV ごとに 4 つの必須列を含め、さらに実行データ項目ごとに列を含める必要があります。4 つの必須列には、各 CSV のマニフェストファイルでこれらの名前を定義することで任意の名前を付けることができます。注: これらの列名は大文字と小文字を区別するため、マニフェストファイルで提供される値と完全に一致する必要があります。
CDB は、スタディ、施設、症例、イベント、およびシーケンスの各列以外のすべての列をデータ項目と見なしてインポートします。1 つのリストにつき、アイテム列は 410 個までです。
| 列 | 説明 | マニフェストファイルのキー |
|---|---|---|
| 試験 |
この列内で、スタディの名前を入力します。スタディには、スタディレコードの名前 ( エクスポートパッケージ生成時にエラーが発生する可能性があるため、この列のヘッダーを「Studyname」にしないでください。
|
スタディ |
| 施設 |
この列には、(Veeva EDC の施設レコードからの) 施設の名前 (施設番号) を入力します。 エクスポートパッケージ生成時にエラーが発生する可能性があるため、この列のヘッダーを「Sitename」にしないでください。
マニフェストファイルで施設列を定義せずに CSV ファイルから列を除外した場合、ワークベンチは症例列に基づいて一致させることができます。その際、ワークベンチは症例 ID がスタディレベルで一意であることを想定してします。 |
施設 |
| 被験者 |
この列には、(Veeva EDC の症例レコードの名前フィールドからの) 症例に対する症例 ID を入力します。 エクスポートパッケージ生成時にエラーが発生する可能性があるため、この列のヘッダーを「Subjectname」にしないでください。
|
症例
|
| 事象 | この列には、データ行に関連するイベント (来院) を記載します。マニフェストファイルの edc_matching の設定に応じて、EDC イベント定義の名前または外部 ID、EDC イベントのイベント日、またはこの列のイベントを使用して、ワークベンチで EDC スケジュールとは別のイベントを作成することができます。また、マニフェストファイルのすべての行にデフォルトのイベントを設定し、この列を完全に除外することで、すべての行をそのイベントに割り当てることができます。イベントマッチングの詳細については以下を参照してください。 | 事象 |
| フォーム *任意 |
この列には、(Veeva EDC のフォーム定義の名前から) データ行に関連付けられたフォームを指定します。この列は、1 つのCSVで複数のフォームのデータをインポートする場合にのみ必要です。この列を含めない場合、ワークベンチは各データ行が単一のフォームのものであると見なします。 フォームマッピングの詳細については、以下を参照してください。 |
フォーム |
| フォーム順序 *繰り返しフォームでは必須で、繰り返しのないフォームでは任意です。 |
フォームが繰り返しである場合、フォームのシーケンス番号です。繰り返しフォームとは、1 つの症例に対する 1 つのイベント中に同じデータが 2 回以上収集されるものを指します。次に、シーケンス番号によってデータ行が一意に識別されます。症例とイベントに複数の行 (フォーム) がある場合、ワークベンチはフォームが繰り返しであると見なし、この列を使用してシーケンス番号を設定します。この列は、フォームが繰り返しである場合は必須ですが、フォームが繰り返しでない場合は任意となります。この場合、ワークベンチはデフォルトで各行のシーケンス番号を「1」に設定します。 ワークベンチのデフォルトのシーケンス番号は「1」であるため、繰り返しフォームにこの列を含めない場合直積集合になることがあり、結果として同じ症例/施設/フォーム/フォームのシーケンス番号識別子を持つ行が生成されます。 20R1 リリースで、「sequence」は「formsequence」に改名されています。20R2 リリース (2020年8月) までは、引き続き「sequence」を使用してデータをインポートすることができます。 |
formsequence |
| アイテムグループ *任意 |
この列には、(Veeva EDC の項目グループ定義の名前から) 後に項目列に関連付けられた項目グループを指定します。この列は、複数の項目グループを持つデータをインポートする場合にのみ必要です。この列を含めない場合、ワークベンチでは、データ行のすべてのアイテムが1つのアイテムグループにあると見なされます。 アイテムグループマッピングの詳細については、以下を参照してください |
項目グループ |
| アイテムグループ順序 *繰り返しアイテムグループでは必須で、繰り返しのないアイテムグループでは任意です |
項目グループが繰り返しである場合、項目グループのシーケンス番号です。繰り返し項目グループとは、1 つの症例に対する 1 つのフォーム中に同じデータが 2 回以上収集されるものを指します。次に、シーケンス番号によってデータ行が一意に識別されます。症例とイベントのフォーム行に項目が 1 セット以上ある場合、ワークベンチはフォームが繰り返しであると見なし、この列を使用してシーケンス番号を設定します。 ワークベンチのデフォルトのシーケンス番号は「1」であるため、繰り返し項目グループにこの列を含めない場合直積集合になることがあり、結果として同じ症例/施設/フォーム/フォームのシーケンス/項目グループ/項目グループのシーケンス番号識別子を持つ行が生成されます。 繰り返しのない項目グループの場合、この列は任意であるため、アイテムグループに繰り返しがない場合は空欄のままにすることも、指定しないこともできます。この場合、ワークベンチはデフォルトで各行のシーケンス番号を「1」に設定します。 |
itemgroupsequence |
| 行ID *任意 21R2以前 |
値を組み合わせて、ワークベンチが行を一意に識別するために使用できる列のリストを指定します。シーケンスを識別するための数値キーがない場合に有効です。例えば、ラボデータをインポートする際に、スタディ、症例、LAB 検査を使用して行を一意に識別することができます。rowid 列のマッピングを含めると、ワークベンチはシーケンスの値を無視して、シーケンスを自動的に「1」に設定します。省略した場合、ワークベンチはデフォルトの配列(スタディ、症例、イベント、フォーム、フォーム順序を使用して行を識別します。rowidへの単一列リストの提供は現在もサポートされておりますが、将来のリリースで削除を予定しています。代わりに、groupid、distinctidをrowid の列のリストとして定義します。行については以下を参照してください。 |
rowid |
| 行ID *任意 21R3以降 |
グループID: これは、21R3リリースより前に作成されたデータインポートのレガシーフィールドです。21R3リリース以降のデータインポートでは、Distinct IDを使用する必要があります。グループIDを使用すると、Distinct IDのようにフォームまたはアイテムグループの順序番号が自動的に増加しないため、データの整合性の問題が発生します。例えば、データでフォームまたはアイテムグループの順序番号が明示的にマッピングされていない場合、デフォルトで1に設定されます。これにより、スタディ、施設、症例、イベント、フォーム、フォーム順序番号、アイテムグループ、アイテムグループ順序番号にまったく同じ値を持つ、複数のレコードがインポートされる可能性があります。その結果、CQLはこれらを重複レコードと見なし、矛盾したリスト結果が発生する可能性があります。 Distinct ID: 列の値を組み合わせてワークベンチがグループのコンテキスト内でレコードを一意に識別するために使用できる列のリストを指定します ( 行外部 ID: EDC からの外部 ID と同様に、外部 ID をデータ行に割り当てることができます。これは、サードパーティのデータに対するクエリのソースを識別する上で役立ちます。行の外部 ID の値を含む列を |
groupid、distinctid、および rowexternalid を持つrowid |
ハイフンのタイプ: ハイフンには「ハイフンマイナス」と「Unicodeハイフン」の 2 つのタイプがあります。ハイフンマイナスは、通常、キーボードの- (ハイフン)キーを押すと得られるキーです。ほとんどのモダンフォントでは、これらの文字は視覚的に同一です。Veeva CDB はデータインポートでハイフンマイナスの使用のみをサポートしています。Unicode ハイフンを含めると、インポートは失敗します。
CSV ファイルの例:
| STUDY_ID | 施設 | SUBJECT_ID | ビジット | イニシャル | DOB | 性別 | 人種 |
|---|---|---|---|---|---|---|---|
| S.Deetoza | 101 | 101-1001 | スクリーニング | CDA | 03-27-1991 | F | ヒスパニック |
この例では、次のように列をマッピングをしています:
- スタディ: STUDY_ID
- 施設: SITE
- 症例: SUBJECT_ID
- イベント: VISIT
INITIALS、DOB、GENDER、RACE 列はすべてデータ項目です。
マニフェストファイル
マニフェストファイルは、CDB のスタディとソースを提供し、ZIP 内のファイルを一覧表示するとともに、各ファイルについて、どの列が必要なデータ ポイントにマッピングされるかを一覧表示します。
ソースは、パッケージの内容を識別するためのカスタム定義値です。この値はワークベンチのソースフィールドに格納されるため、これを使用して、CQL)を介してワークベンチでこのパッケージのデータを識別することができます。ソースの値は、スタディ内で一意である必要があります。
スタディには、スタディレコードの名前 (study__v) を記入します。スタディには、スタディレコードの名前 (study__v) を記入します。スタディ名に空白文字が含まれている場合、マニフェストファイルでは空白文字を含む値を使用する必要がありますが、データファイルでは空白文字をアンダースコア (_) に置き換える必要があります。
ソースには、データのソースを指定します。システムは、インポートされたすべてのデータにこのソースを適用します。次に、各 CSV ファイルのファイル名 (拡張子付き) とその列のマッピングを「データ」の値として配列で一覧化します。
インポートファイルに、各データ項目に関する設定メタデータを含めるまたは含めないかを選択することができます。詳しくは以下を参照してください。
このファイルを「manifest.json」として保存します。
注: ワークベンチは、この正確なファイル名(大文字と小文字を区別)と拡張子を持つマニフェストファイルのみを受け入れます。
マニフェストの例: 単一のフォーム
以下は、調査票を含む、eCOA からパッケージをインポートする、Deetoza のスタディに関するマニフェストファイルの例です:
{ "study": "Deetoza", "source": "eCOA", "data": [ { "filename": "Survey.csv", "study": "protocol_id", "site": "site_id", "subject": "patient", "event": "visit_name" } ] } マニフェストの例: 複数のフォーム
以下は、化学および血液学フォームを含む、研究所ベンダーからパッケージをインポートする、Deetoza のスタディに関するマニフェストファイルの例です:
{ "study": "Deetoza", "source": "lab", "data": [ { "filename": "Chemistry.csv", "study": "STUDY_ID", "site": "SITE_ID", "subject": "SUBJECT_ID", "event": "VISIT", "formsequence": "LAB_SEQ" }, { "filename": "Hematology.csv", "study": "STUDY_ID", "site": "SITE_ID", "subject": "SUBJECT_ID", "event": "VISIT", "formsequence": "LAB_SEQ" } ] } また、行 ID のマッピングを使用することで、1つの CSV ファイルで 化学 & 血液学研究所データをインポートすることもできます。CSV ファイルでは、Lab Test Set 列を使用して、行の科学または血液学を示すことができます。
{ "study": "Deetoza", "source": "lab", "data": [ { "filename": "Labs.csv", "study": "STUDY_ID", "site": "SITE_ID", "subject": "SUBJECT_ID", "event": "VISIT" } ] } フォームラベル上書き
サードパーティーのデータソースをインポートする場合、フォームに対して、form_labelキーをマッピングすることで、ラベルを定義できます。このラベルは、リスト内でCQLを使用して参照できます。
form_label キーを使用する 2 つの異なる方法があり、フォーム キーがマニフェストで使用されているかどうかに応じて、期待される入力が異なります。
フォーム キーがデータファイルの列にマッピングできるようマニフェストで使用され、form_label キーも使用される場合、form_label キーの入力もフォームラベルを見つけることができるデータファイルの列を表すことになります。form_label キーは、フォームのキーとともに以下のデータ配列の一部となります:
{ "study": "Deetoza", "source": "lab", "data": [ { "filename": "hematology_lpanel.csv", "study": "STUDY_ID", "site": "SITE_ID", "subject": "SUBJECT_ID", "event": "VISIT", "formsequence": "LAB_SEQ", "form": "FORM_NAME_COLUMN" "form_label": "FORM_LABEL_COLUMN" } ] } フォーム キーが使用されず、form_label キーがマニフェストで使用される場合、form_label キーに期待される入力は文字列であり、その文字列値は使用されるフォームラベルと同じです。フォームのラベルを定義するには、ラベル form_label をデータ配列に追加します:
{ "study": "Deetoza", "source": "lab", "data": [ { "filename": "hematology_lpanel.csv", "study": "STUDY_ID", "site": "SITE_ID", "subject": "SUBJECT_ID", "event": "VISIT", "formsequence": "LAB_SEQ", "form_label": "Hematology" } ] } 項目の名前とラベルを上書きするには、項目の設定に名前とラベルのプロパティを追加します。詳しくは以下を参照してください。
任意: イベントのマッチング
デフォルトでは、ワークベンチはフォームの CSV ファイルのイベントを、Veeva EDC の一致するイベント定義レコードの名前と照合します。また、ワークベンチがイベント定義の外部 ID に基づいてイベントと照合するように選択することもできます。また、マニフェストファイルにデフォルトのイベントを定義し、すべての行をそのイベントに自動的に割り当てることもできます。データが EDC でスケジュールされたイベント以外で収集された場合、どの EDC イベントにもマッピングしないように選択し、必要に応じてインポートパッケージ内のイベントと一致するようにイベントを作成することもできます。
イベントが繰り返しイベントグループ内にある場合、ワークベンチはイベント定義の外部 ID を使用し、照合するためのシーケンス番号を付加します。シーケンス番号は、ファイル内の一意のイベントごとに増加します。イベントが複数のイベントグループで再利用される場合は繰り返しとはみなされません。代わりに、ワークベンチは EDC スケジュールの最初に一致するイベントとマッチングさせます。
デフォルトの挙動
マニフェストファイルにイベントマッチングの設定を含めない場合、次のデフォルトが適用されます:
- ワークベンチは、イベント定義の名前を使用して照合を行います。
- ワークベンチは、既存の EDC イベントとの照合を試みます。EDC に一致するイベントがない場合、ワークベンチは新しいイベントを作成します。
このデフォルトの挙動は、次のマニフェスト設定と同等です:
{ "study": "Deetoza", "source": "Labs", "edc_matching": { "event": { "target": ["name"], "generate": true } } } 名前との照合 (デフォルト)
マニフェストファイルに edc_matching を含めない場合、ワークベンチは自動的にイベント定義の名前を使用して照合します。マニフェストファイルで名前ベースのバッチ処理を指定することも可能です。
{ "study": "Deetoza", "source": "Labs", "edc_matching": { "event": { "target": ["name"] } } } 外部 ID との照合
イベント定義の外部 ID (旧 OID) で照合するには、edc_matching を含め、イベントターゲットを external_id に設定する必要があります。以下の抜粋例をご確認ください:
{ "study": "Deetoza", "source": "Labs", "edc_matching": { "event": { "target": ["external_id"] } } } デフォルトのイベントを設定します
CSV にイベントを記載する代わりに、マニフェストファイルからイベントをデフォルトのイベントとして選択することができます。すると、ワークベンチによってその CSV ファイルのすべての行にそのイベントが割り当てられます。これは、デフォルトキーによって制御されます。デフォルトには、イベント定義の名前を使用します。特定のデータファイルに対するデフォルトを設定することも、パッケージレベルでデフォルトを設定することも可能です。
例: パッケージレベルのデフォルトイベント
{ "study": "Deetoza", "source": "lab", "edc_matching": { "event": { "default": "treatment_visit" } }, "data": [ { "filename": "Labs.csv", "study": "STUDY_ID", "site": "SITE_ID", "subject": "SUBJECT_ID", "event": "VISIT", "rowid": ["LAB_TEST_SET", "LAB_TEST_SEQ"] } ] } 例: ファイルレベルのデフォルトイベント
{ "study": "Deetoza", "source": "Labs", "edc_matching": { "event": { "default": "treatment_visit", } } } 一致しないイベントの処理
デフォルトでは、ワークベンチが名前または外部 ID で EDC 内のイベントと一致させることができない場合、ワークベンチはソースに固有の EDC 以外のイベントに対して新しいイベントを作成します。作成された新しいイベントは、ワークベンチヘッダーイベントレコード全体の一部になります (@HDR.Eventから CQL 経由でアクセス可能)。これは、生成キーによって制御されます。デフォルトの挙動に対するマニフェストの設定は generate: trueです。データが EDC イベントスケジュール以外で収集された場合、generate を false に設定することで、どの EDC イベントとも照合しないように選択することができます。Generate を false にした場合、ワークベンチは新しいイベント定義を作成しなくなります。代わりに、一致する EDC イベントがない行のインポートが失敗するようになります。
例: 外部 ID で照合し、一致しないイベントを無視します
{ "study": "Deetoza", "source": "Labs", "edc_matching": { "event": { "target": ["external_id"], "generate": false } } } すべてのデータが EDC のスケジュール以外で収集されたものである場合、ワークベンチに EDC イベントとの照合をさせずに、各イベントに対して新しいイベントを作成させるように選択することができます。これを行うには、以下の例に示すように、イベントを false に設定します:
{ "study": "Deetoza", "source": "Labs", "edc_matching": { "event": false } } 任意: フォームとアイテムグループのマッピング
データセット内の繰り返しフォームと項目グループのワークベンチでの解釈方法の定義を含め、CSV の行を異なるフォームと項目グループにマッピングするよう選択することができます。これによりワークベンチは 1 つの CSV を、単一のフォームと単一項目グループではなく、複数のフォームと項目グループに変換できるようになります。
例えば、LABフォームには、複数の項目グループ (各LABテストカテゴリごとに 1 つの項目グループ) を設定することができます。行のデータ項目がどの項目グループに属するかを示すには、itemgroup 列を使用します。ワークベンチでは、行内のマッピングされていない列はすべて項目として扱います。ワークベンチは、行の指定された項目グループ内のそれらの項目をインポートします。これらの列には、項目設定で追加のメタデータを指定することができます。詳しくは以下を参照してください。
以下の表は、フォームと項目グループの構成シナリオが異なる場合、ワークベンチがどのようにデータを扱うかを理解するためのものです:
| フォームの定義 | 項目グループの定義 | 結果 |
|---|---|---|
| いいえ | いいえ | ワークベンチでは、各行が 1 つのフォームのものであるとして扱われます。 |
| はい | いいえ | ワークベンチでは各行は異なるフォームとして扱われ、フォーム列によってフォームが特定されます。フォーム列の一意な値は、それぞれ別のフォームとして扱われます。 |
| いいえ | はい | ワークベンチは、各行を (itemgroup 列で定義された) 項目グループのインスタンスとして扱い、これらの行を症例とフォームでグループ化します。各項目グループを繰り返し項目グループとして扱うには、itemgroupsequence 列を使用します。 |
| はい | はい | ワークベンチは、行を症例、フォーム、および itemgroup でグループ化します。フォーム列の一意の値は別のフォームとして扱われ、itemgroup列の一意の値は項目グループになります。 |
マニフェストの例: 複数のフォーム
次の例では、「Labs.csv」ファイルに複数のフォームが含まれています。これらは、「Labs.csv」ファイルのフォーム列で識別されます。
{ "study": "Deetoza", "source": "lab", "data": [ { "filename": "Labs.csv", "study": "protocol_id", "site": "site_id", "subject": "subject_id", "event": "visit", "form": "form" } ] } 
マニフェストの例: 複数の項目グループ
次のマニフェストファイルの例では、Labs フォームに複数の項目グループがあります。これらは、「Labs.csv」ファイルのlab_category列で識別されます。
{ "study": "Deetoza", "source": "lab", "data": [ { "filename": "Labs.csv", "study": "protocol_id", "site": "site_id", "subject": "subject_id", "event": "visit", "item_group": "lab_category" } ] } 
オプション: コードリストの設定
コードリスト を、コードリストタイプアイテム から参照するように設定できます。コードリストは、ユーザがデータを入力する際に選択できるコードとデコードのペアのセットです。
各コードリストに対して、name、external_id (任意)、codelist_dataを入力します。codelist_dataは、codeとdecodeのペアを受け入れます。
"codelists": [ { "name": "SEX", "external_id": "SEX", "codelist_data": [ { "code": "M", "decode": "Male" }, { "code": "F", "decode": "Female" } ] } ] 任意: 項目の設定
CDB マニフェストファイル内に、データワークベンチでのデータ項目の処理方法を知らせる項目メタデータを含めることができます。各項目にデータ型を指定したり、選択したデータ型に応じて追加のプロパティを指定することもできます。
項目の設定を省略した場合、CDB ワークベンチはすべての項目をテキストとして扱います。
シンプルな構成と詳細な設定の比較
項目「config」オブジェクトには、simple (簡易) と advanced (詳細) の2つの構成形式があります。簡易設定では、項目のデータ型のみを指定します。項目のプロパティにはデフォルト値を使用します。詳細設定では、データ型とプロパティを指定します。
"items" { "Weight": "float" }"items" { "Weight": { "type": "float", "precision": 2 } }名前とラベルの定義
項目の名前とラベルを設定で定義することができます。これらのキーは、すべての項目データ型とのマッピングに利用可能です。
ラベルキーをマッピングしてラベルを提供します。省略された場合、この値はデフォルトで項目の名前と一致します。デフォルトでは、ワークベンチでは、列のヘッダーを項目の名前として使用します。マニフェストファイルの name_override キーをマッピングすることで、これを上書きできます。名前、英数字、ダッシュ、アンダースコアのみを含めることができます。空白は許可されません。
"items": { "REQ_NUM": { "type": "text", "length": 10, "name_override": "REQUESTION_NUM", "label": "Requisition Number" }, "EVENTTYP": { "type": "text", "length": 10, "label": "Event Type" }, "COL_DATE": { "type": "date", "format": "ddMMMyyyy", "name_override": "COLLECTION_DATE", "label": "Collection Date" }, "COL_TIME": { "type": "time", "format": "HH:mm", "label": "Collection Time" } } データ型別の利用可能可能なプロパティ
データ型ごとに使用可能な設定プロパティが異なります。
| データタイプ | 設定例: | プロパティ | プロパティの説明 |
|---|---|---|---|
| テキスト |
|
長さ | 使用できる文字数。デフォルト長さは 1500 です。 |
| 整数 |
|
最低 | 使用できる最小 (最低) 値。デフォルトは -2,147,483,647 です。 |
| 最高 | 使用できる最大 (最高) 値。デフォルトは 2,147,483,647 です。 | ||
| 浮動 |
|
長さ |
小数点の左右両方に使用できる最大桁数。 最大値がこのプロパティよりも桁数が多い場合、ワークベンチはその数値を代わりに使用します。 |
| 精度 |
使用できる小数点以下の桁数.デフォルトは 5 です。 最大値がこのプロパティよりも小数点以下の桁数が多い場合、ワークベンチはその数値を代わりに使用します。 |
||
| 最低 | 使用できる最小 (最低) 値。デフォルトは -4,294,967,295 です。 | ||
| 最高 | 使用できる最大 (最高) 値。デフォルトは 4,294,967,295 です。 | ||
| 日付 |
|
フォーマット |
日付値の変換に使用するフォーマットパターン。サポートされている日付形式の一覧については以下を参照してください。 デフォルトは「yyyy-MM-dd」です。 |
| 日時 |
|
フォーマット |
日時値の変換に使用するフォーマットパターン。サポートされている日時形式の一覧については以下を参照してください。 デフォルトは「yyyy-MM-dd HH:mm」です。 |
| 時間 |
|
フォーマット |
時間値の変換に使用するフォーマットパターン。サポートされている時間形式の一覧については以下を参照してください。 デフォルトは「HH:mm」です。 |
| ブーリアン |
|
該当なし | ブーリアンデータ型には、設定プロパティはありません。 ワークベンチはブーリアン値に「true」/「false」、「yes」/「no」、「1」/「0」を許可しています。 |
| コードリスト |
|
コードリスト | このアイテムが使用するコードリストを指定します。コードリストは、ユーザがデータ入力時に選択できるコードとデコードのペア (コードリストアイテム) の定義されたリストです。上記のコードリストの定義方法 を参照してください。 |
サポートされている日時のフォーマットパターン
日付、日時、時刻の項目には、次のフォーマットパターンがあります。日時項目の場合、日付と時刻のパターンを組み合わせます。例:「yy-MM-dd HH:mm」。日付に時刻フォーマットパターン (またはその逆) を使用した場合、インポートはエラー (D-012) で失敗します。
| フォーマットパターン | 例 | 説明 |
|---|---|---|
| dd MM yy | 02 18 20 | 2 桁の日、2 桁の月、2 桁の年、区切り文字に空白 ( ) を使用 |
| dd MM yyyy | 02 18 2020 | 2 桁の日、2 桁の月、4 桁の年、区切り文字に空白 ( ) を使用 |
| dd MMM yyyy | 02 Feb 2020 | 2 桁の日、略称月 (テキスト)、4 桁の年、区切り文字に空白 ( ) を使用 |
| dd-MM-yy | 18-02-20 | 2 桁の日、2 桁の月、2 桁の年、区切り文字にダッシュ (-) を使用 |
| dd-MM-yyyy | 18-02-2020 | 2 桁の日、2 桁の月、4 桁の年、区切り文字にダッシュ (-) を使用 |
| dd-MMM-yyyy | 18-Feb-2020 | 2 桁の日、略称月 (テキスト)、4 桁の年、区切り文字にダッシュ (-) を使用 |
| dd-MMM-yyyy HH:mm:ss | 18-Feb-2020 12:10:50 | 2 桁の日、略称月 (テキスト)、4 桁の年、区切り文字にダッシュ (-) を使用、時間に秒を含める |
| dd/MMM/yy | 18/Feb/20 | 2 桁の日、略称月 (テキスト)、2 桁の年、区切り文字にスラッシュ (/) を使用 |
| dd-MMM-yy | 18-Feb-20 | 2 桁の日、略称月 (テキスト)、2 桁の年、区切り文字にダッシュ (-) を使用 |
| ddMMMyy | 18Feb20 | 2 桁の日、略称月 (テキスト)、2 桁の年 (区切り文字なし) |
| dd MMM yy | 18 Feb 20 | 2 桁の日、略称月 (テキスト)、2 桁の年、区切り文字に空白 ( ) を使用 |
| dd.MM.yy | 18.02.20 | 2桁の日、2桁の月、2桁の年、区切り文字にピリオド(.)を使用 |
| dd.MM.yyyy | 18.02.2020 | 2桁の日、2桁の月、4桁の年、区切り文字にピリオド(.)を使用 |
| dd/MM/yy | 18/02/20 | 2 桁の日、2 桁の月、2 桁の年、区切り文字にスラッシュ (/) を使用 |
| dd/MM/yyyy | 18/02/2020 | 2 桁の日、2 桁の月、4 桁の年、区切り文字にスラッシュ (/) を使用 |
| ddMMMyyyy | 18Feb2020 | 2 桁の日、略称月 (テキスト)、4 桁の年 (区切り文字なし) |
| ddMMyy | 180220 | 2 桁の日、2 桁の月、2 桁の年 (区切り文字なし) |
| ddMMyyyy | 18022020 | 2 桁の日、2 桁の月、4 桁の年 (区切り文字なし) |
| MM/dd/yy | 02/18/20 | 2 桁の月、2 桁の日、2 桁の年、区切り文字にスラッシュ (/) を使用 |
| MM/dd/yyyy | 02/18/2020 | 2 桁の月、2 桁の日、4 桁の年、区切り文字にスラッシュ (/) を使用 |
| MMddyy | 021820 | 2 桁の月、2 桁の日、2 桁の年 (区切り文字なし) |
| MMddyyyy | 02182020 | 2 桁の月、2 桁の日、4 桁の年 (区切り文字なし) |
| MMM dd yyyy | Feb 18 2020 | 略称月 (テキスト)、2 桁の日、4 桁の年、区切り文字に空白 ( ) を使用 |
| MMM/dd/yyyy | Feb/18/2020 | 完全な月 (テキスト)、2 桁の日、4 桁の年、区切り文字にスラッシュ (/) を使用 |
| MMMddyyyy | Feb182020 | 完全な月 (テキスト)、2 桁の日、4 桁の年 (区切り文字なし) |
| yy-MM-dd | 20-02-18 | 2 桁の年、2 桁の月、2 桁の日、区切り文字にダッシュ (-) を使用 |
| yy/MM/dd | 20/02/18 | 2 桁の年、2 桁の月、2 桁の日、区切り文字にスラッシュ (/) を使用 |
| yyyy MM dd | 2020 02 18 | 4 桁の年、2 桁の月、2 桁の日、区切り文字に空白 ( ) を使用 |
| yyyy-MM-dd | 2020-02-18 | 4 桁の年、2 桁の月、2 桁の日、区切り文字にダッシュ (-) を使用 |
| yyyy-MM-dd'T'HH:mm | 2020-02-18T12:10 | 4 桁の年、2 桁の月、2 桁の日、区切り文字にダッシュ (-) を使用、時間付き |
| yyyy.dd.MM | 2020.18.02 | 4桁の年、2桁の日、2桁の月、区切り文字にピリオド(.)を使用 |
| yyyy.MM.dd | 2020.02.18 | 4桁の年、2桁の月、2桁の日、区切り文字にピリオド(.)を使用 |
| yyyy/MM/dd | 2020/02/18 | 4 桁の年、2 桁の月、2 桁の日、区切り文字にスラッシュ (/) を使用 |
| yyyyMMdd | 20200218 | 4 桁の年、2 桁の月、2 桁の日 (区切り文字なし) |
| yyyyMMdd'T'HH:mm | 2020218T12:10 | 4 桁の年、2 桁の月、2 桁の日 (区切り文字なし) 時間付き |
| dd/MM/yyyy HH:mm | 18/02/2020 18:30 | 2 桁の日、2 桁の月、4 桁の年、区切り文字にスラッシュ (/) を使用、24時間表記の時間 |
| MM/dd/yyyy HH:mm | 02/18/2020 18:30 | 2 桁の月、2 桁の日、4 桁の年、区切り文字にスラッシュ (/) を使用、24時間表記の時間 |
| yyyy-MM-dd'T'HH:mm:ss+HH:mm | 2020-02-18T18:30:22+00:00 | 4 桁の年、2 桁の月、2 桁の日、区切り文字にダッシュ (-) を使用、24時間表記の時間と秒、UTC からの時刻オフセット (+HH:mm) 注: マニフェストファイルでは、T を一重引用符 (‘) で囲む必要がありますが、CSV ファイルでは使用しないでください。 |
| yyyy-MM-dd'T'HH:mm:ssZ | 2020-02-18T18:30:22Z | 4 桁の年、2 桁の月、2 桁の日、区切り文字にダッシュ (-) を使用、24時間表記の時間と秒 (UTC 時間) 注: マニフェストファイルでは、T を一重引用符 (‘) で囲む必要がありますが、CSV ファイルでは使用しないでください。 |
| yyyyMMdd'T'HH:mm:ssZ | 20200218T18:30:22Z | 4 桁の年、2 桁の月、2 桁の日、24時間表記の時間と秒 (UTC 時間) 注: マニフェストファイルでは、T を一重引用符 (‘) で囲む必要がありますが、CSV ファイルでは使用しないでください。 |
| yyy-MM-dd'T'HH:mm:ss | 2020-2-18T12:10:41 | 1年、2桁の月、2桁の日付を、秒を含む時刻とともに、ハイフン(-)を区切り文字として使用します。 注: マニフェストファイルでは、T を一重引用符 (‘) で囲む必要がありますが、CSV ファイルでは使用しないでください。 |
| ddMMyyyy'T'HH:mm:ssZ | 10122024T16:15:30 | 2桁の日付、2桁の月、4桁の年、区切り文字なし、24時間制 注: マニフェストファイルでは、T を一重引用符 (‘) で囲む必要がありますが、CSV ファイルでは使用しないでください。 |
| yyyyMMdd HH:mm:ss | 20241210 16:15:30 | 4桁の年、2桁の月、2桁の日、区切り文字なし、24時間制で秒を含む |
| MM/dd/yyyy HH:mm: | 12/10/2024 16:15:30 | 2桁の月、2桁の日、4桁の年、区切り文字としてスラッシュ(/)、秒を含む24時間制 |
| yyyy-MM-dd'T'HH:mm:ss | 2024-12-10T16:15:30 | 4桁の年、2桁の月、2桁の日、区切り記号としてダッシュ(-)、24時間制 注: マニフェストファイルでは、T を一重引用符 (‘) で囲む必要がありますが、CSV ファイルでは使用しないでください。 |
| HH:mm | 18:30 | 24 時間表記 |
| HH:mm:ss | 18:30:15 | 24時間表記の時間と秒 |
パッケージの例: 単一のフォーム、項目メタデータ
ここでは、Verteo Pharma のランダム化ベンダーからの (項目のメタデータを含むランダム化フォームを含む) インポートパッケージの例を紹介します:
manifest.json:
{ "study": "Cholecap", "source": "IRT", "data": [{ "filename": "Randomization.csv", "study": "protocol_id", "site": "site_id", "subject": "patient", "event": "visit_name", "items": { "randomization_number": { "type": "integer", "length": "14" }, "date_of_randomization": { "type": "date", "format": "yyyy-MM-dd" } } }] } Randomization.csv:
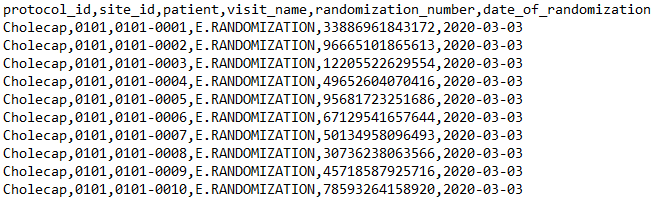
厳格なインポート
マニフェストファイルの厳格なインポートパラメータを使用すると、データCSVファイル内のすべてのアイテム列ではなく、マニフェストで定義されたアイテムのみにデータの取り込みを制限することができます。このオプションはパッケージ全体または個々のファイルに適用できます。ファイルレベルの設定はパッケージレベルの設定を上書きします。
strict_importパラメータは、正または誤を受け入れます。これを正に設定すると、厳格なインポートが有効になります。
任意: データの制限 (盲検化)
項目、行、リストデータファイル、ソースレベルでデータを制限 (盲検化) して、制限付きデータへのアクセス権を持たないユーザに対してデータを非表示にすることができます。例えば、スタディでは、該当するスタディ薬を使用している被験者の研究所のみを指定して注文する場合があります。被験者がどの研究所に所属しているかを知ることで、被験者の盲検を解除することができます。この情報を制限することで、盲検化済みユーザがこれらの被験者を識別できないようにすることができます。
| 制限レベル | マニフェストファイルの設定 |
|---|---|
| 項目 |
|
| フォームレコード *インポートされる特定のフォームレコードのデータを制限します。その行が盲検化済みかどうかを示す列を使用します。 |
|
| データファイルの一覧化 |
|
| ソースパッケージ |
|
制限付きデータへのアクセス権を持つユーザ (通常はリードデータ管理者) に対しては、制限付きデータも制限の無いデータと同じように動作します。盲検化済みユーザ (制限付きデータへのアクセス権を持たないユーザ) の場合、インポートされた制限付きデータには次の動作ルールが適用されます:
- 項目 (列) が制限付きの場合:
- CQL プロジェクションは、制限付き項目の列を返しません。
- CQL プロジェクションは、制限付き項目を参照する派生列を返しません。
- 盲検化済みユーザが CQL 文で制限付き項目を参照した場合も、CQL はその列を返しません。
SHOWおよびDESCRIBEは制限付き項目を返しません。
- 行が制限されている場合:
- 結果セットは、フォームまたは項目グループから行を返しません。
- リストファイル (csv) が制限されている場合:
- デフォルトの
@HDR列はリストに含まれますが、項目列はリストに含まれません。
- デフォルトの
- ソース (パッケージ) が制限されている場合:
- CQL は、制限付きソースの項目または列は、どのリストからも結果を返しません。
- CDB は、ソース内のすべての項目定義、項目グループ定義、フォーム定義を制限付きとしてマークします。
- すべてのデータ行が制限付きとしてマークされます。
- デフォルトの @HDR 列は、引き続きコアリストに表示されます。
ZIP パッケージ
マニフェストファイルと CSV の作成が完了したら、ファイルをまとめて zip 圧縮します。zip 圧縮する前にこれらのファイルをフォルダ内に置かないでください。この ZIP フォルダには任意の名前を付けることができます。ただし、「Study-Name_Source_datetime.zip」のように、一意となる識別子を使用して命名することをお勧めします。ZIP フォルダ内にはフォルダを含めないでください。すべての CSV ファイルとマニフェストファイルは同じレベルにある必要があります。
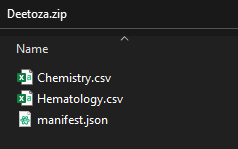
Vault の FTP サーバへのアクセス
ドメイン内の各 Vault には、独自の FTP ステージングサーバがあります。FTP サーバは、Vault へアップロードするファイルまたは Vault から抽出するファイル用の一時的なストレージ領域です。
サーバ URL
各ステージングサーバの URL は、対応する Vault と同じです。例: veepharm.veevavault.com。
FTP サーバにアクセスする方法
ステージングサーバは、お使いの FTP クライアントまたはコマンドラインからアクセスできます。
以下の設定を FTP クライアントに使用する:
- プロトコル: FTP (ファイル転送プロトコル)
- 暗号化: TLS に対して明示的な FTP を必要とします (FTPS)。これはセキュリティ要件です。お使いのネットワークインフラストラクチャが FTPS トラフィックをサポートしている必要があります。
- ポート: 通常は追加する必要はなく、Port 21 にデフォルト設定されます。
- ホスト: {DNS}.veevavault.com。例: “veepharm” は veepharm.veevavault.com の DNS です。
- ユーザ: {DNS}.veevavault.com+{USERNAME}。これはログインしたユーザ名と同じものを使用します。例: veepharm.veevavault.com+tchung@veepharm.com。
- パスワード: この Vault にログインするためのパスワード。これは、標準ログインに使用されているのと同じパスワードです。
- ログインタイプ: 通常
- ファイルの転送タイプ: バイナリとしてファイルを転送
大容量ファイルをアップロードする際に問題が発生した場合、FTPクライアントのタイムアウト設定を180秒に増やしてください。
プロキシまたはファイアウォールでリモート検証を有効にしている場合、ネットワーク上のコンピューターからVeeva FTPサーバへのFTPトラフィックが拒否される可能性があります。リモート検証を無効化する際には IT 部門にご相談ください。無効化できない場合、Veeva サポートにお問合せください。
FTP のディレクトリ構造
ユーザディレクトリの中には、「workbench」ディレクトリがあります。ここに、サードパーティのデータをアップロードします。ここに置かれたファイルは CDB に自動的に認識されます。
インポートが正常に終了すると、ファイルは「workbench/_processed」に移動されます。詳しくは以下を参照してください。
データのインポート
ワークベンチにデータをインポートする方法は2つあります。FTPクライアントを使用するか、CDBユーザインタフェース内のCDBパッケージローダを使用する方法です。
FTPクライアントを使用したインポート
FTPクライアントを使用してデータをインポートするには、任意のFTPクライアントを使用して、ZIPファイルをFTPステージングサーバの「workbench」ディレクトリにアップロードします。ZIP を FTP ステージングサーバにアップロードすると、CDB によってインポートとデータ変換が行われます。
CDBパッケージローダを使用したインポート
ワークベンチのユーザインタフェースを使用してデータをインポートするには、CDBパッケージローダを介してZIPファイルをアップロードします。
CDBパッケージローダにアクセスするには:
-
上部のナビゲーションバーで、データパッケージのアップロード (Upload Data Packages)をクリックするか、ナビゲーションドロワーからパッケージローダ (Package Loader)をクリックします。
-
ZIPファイルをドラッグアンドドロップ (Drag and drop)エリアにドラッグアンドドロップします。このエリアをクリックし、ファイルを参照してアップロードすることもできます。

- アップロードしたファイルは、選択したパッケージ (Selected Packages)の下に表示されます。ファイルを削除するには、Xをクリックします。
- アップロードをクリックします。
一度にアップロードできるパッケージ数は最大10個で、各ファイルの最大サイズは200 MBです。ファイルがこの制限を超えると、エラーメッセージが表示され、システムがアップロードを阻止します。
インポートが完了すると、ワークベンチから、あなたとソースに登録されている他のユーザ宛てに電子メール通知が送信されます。パッケージの再処理の結果、以前の読み込み内容から変更があった場合、ワークベンチからあなたとそのソースに登録されているユーザ宛てに通知が送信されます。
インポートの成功
インポートに成功した場合:
- CDB によって、すべての定義レコードとそれらの関係が作成されます。
- CDB ではデータソースを一意に識別するため、インポートされたすべてのレコードのマニフェストで指定された値を使用してソースフィールドが自動的に設定されます。(Veeva EDCから取り込んだフォームは、この値が自動的に「EDC」に設定されます。サードパーティのデータソースとOpenEDCの一次ソースでは、「EDC」という名前は使用できません。)
- インポートパッケージ内の一意なフォームごとにコアリストが作成されます。詳しくは以下を参照してください。
- CDBによって、インポートZIPファイルは次のように移動されます:
- 「workbench」から「workbench/_processed/{study}/{source}」に移動されます(インポートにFTPクライアントを使用した場合)。また、CDB によってインポートの日付と時刻がファイル名に追加されます。
- Vaultファイルステージングから「workbench/_processed/{study}/{source}」に移動されます(インポートにパッケージローダを使用した場合)。
以上で、ワークベンチでリストを表示できるようになります。現在のリリースでは、ワークベンチに新しいリストがすぐに表示するわけではありません。まず、スタディのリストページに移動し、別のコアリストをクリックして開いた後、リストページに戻ります。その後、新しいデータリストがリストに表示されます。以上で、リストの名前をクリックすることでそのリストを開くことができます。
失敗したインポート
インポートに成功した場合:
- CDB はインポートを試みた日時を ZIP ファイルのファイル名に追加します。
- CDBによって、インポートZIPファイルは次のように移動されます:
- 「workbench」から「workbench/_error」に移動されます(インポートにFTPクライアントを使用した場合)
- Vaultファイルステージングから「workbench/_error」に移動されます(インポートにCDBパッケージローダを使用した場合)
- CDBによってエラーログ(「<import datetime>_<package name>_errors.csv」)が作成されます。
考えられるエラーの一覧とその解決方法を参照してください。
エラー制限: インポートログに取得できるエラーおよび警告の件数は最大 1 万件のみとなっており、このしきい値に達すると記録が停止されます。
ソースとインポートパッケージの確認
スタディのソースおよび関連するインポートパッケージは、インポート (Import)ページから確認できます。
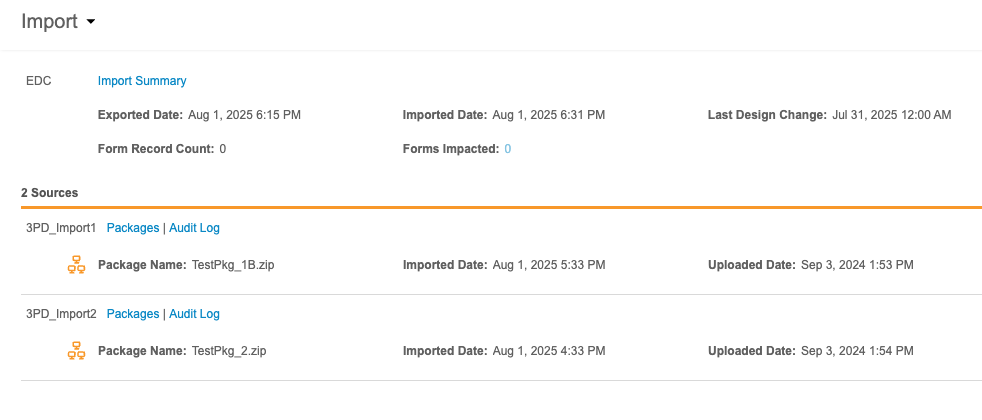
このページの上部には、一次ソースのインポート情報(そのソースがVeeva EDCであるか、サードパーティのEDCシステムであるか)が表示されます。このヘッダーには、次の情報が含まれます。
- インポートの概要をダウンロードするためのリンク
- エクスポート日(このデータがEDCシステムからエクスポートされた日付)
- インポート日(このデータがワークベンチにインポートされた日付)
- 最終デザイン変更(EDCシステムにおける最終スタディデザイン/プロトコール変更の日時)
- フォームレコード数(新しくインポートされたパッケージの影響を受けるフォームレコードの数)
- 影響を受けたフォーム(新しくインポートされたパッケージによって影響を受けたフォームの数)
インポートの概要には、Veeva EDCからのすべての増分ロードが要約されます。これには、各日について以下の情報が含まれます。
- 日付
- #増分パッケージの数(この日にインポートされた増分パッケージの数)
- #フルパッケージの数(この日にインポートされたフルパッケージの数)
- エラー(インポート中にエラーが発生したかどうか「はい」または「いいえ」で示します)
このリストは、インポート日付範囲 (Import Date Range)でフィルタリングできます。
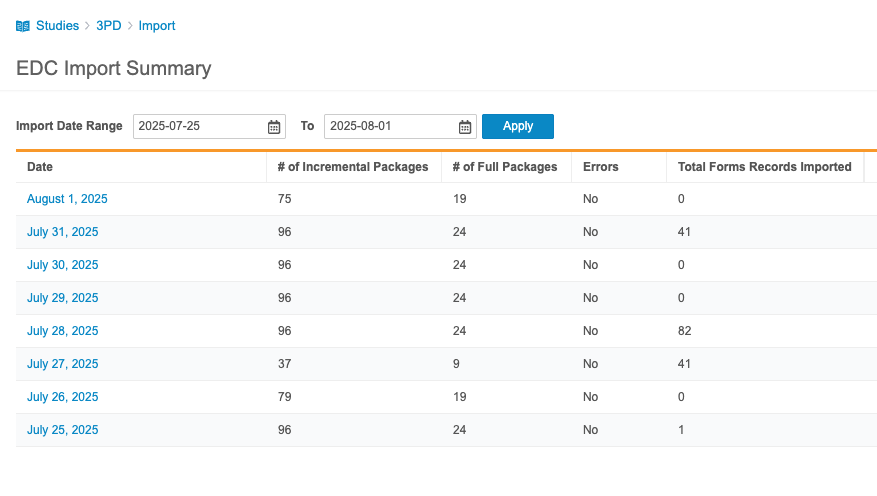
日付 (Date)をクリックすると、その日のすべてのパッケージを確認できます。ワークベンチでは、インポートパッケージごとに次の情報が表示されます:
- EDCエクスポート日
- アップロード日
- インポート日
- フルロード(true/falseチェックボックス)
- インポートされたフォームレコードの合計数
- ステータス
- 詳細
変更を加えたインポートの確認と承認
CDB にインポートされるデータが、承認されたフォーマットや構造から変更されないようにするため、CDB は各サードパーティのソースごとに、ある時点の読み込み内容から次の時点の読み込み内容に対するパッケージ構成の変更を検出するようになっています。
システムがパッケージ、ファイル、または盲検化レベルでの設定の変更、または CSV ファイル構造の変更を検出した場合、CDB はインポート処理を一時停止します。承認権限を持つユーザがパッケージを承認または却下するまで、パッケージに対する処理は行われず、一時停止ステータスになります。ユーザがパッケージを承認すると、CDB は承認理由を記録した上でデータパッケージをインポートします。パッケージが承認されると、CDB は登録者に承認された変更内容をメールで通知します。CDB は、関連するすべてのリストとビューに変更インジケータを表示します。このインジケーターを閉じて、任意のリストまたはビューのフォーム変更ログをダウンロードすることができます。ユーザがパッケージを却下すると、CDB は却下理由を記録した上でパッケージに拒否をマークし、未インポートステータスを割り当てます。その後、CDB はソースの最後に正常にインポートされたデータパッケージへと戻します。
パッケージのステータスが一時停止になると、同じソースに対してアップロードされた他のすべてのパッケージはキューに入り、一時停止されたパッケージが承認または却下されるまで待機します。一時停止中のパッケージが承認または却下されると、CDB は処理のために最後にキューに入れられたパッケージにスキップします。最後に一時停止されたパッケージとキュー内の最後のパッケージの間にあるパッケージは処理されません。例えば、「パッケージ 1」をアップロードして一時停止した後、「パッケージ 1」がまだ一時停止状態のままパッケージ 2~5 をアップロードした場合、「パッケージ1」が承認または却下されると、CDB は「パッケージ 5」にスキップし、パッケージ 2~4 は未処理のままとなります。
新規のソースを使用しはじめてアップロードされたパッケージの場合、CDB は自動的に一時停止ステータスを適用し、そのソースからのデータがシステムに表示される前に、ユーザはその初回のパッケージを承認または却下する必要があります。
ワークベンチでは、承認が必要なパッケージについて差分と関連オブジェクトのタブを持つパッケージ詳細パネルが表示されるようになりました。差分タブには、マニフェストの現在と前回のパッケージの変更内容が表示されます。ユーザは、前回と現在の変更内容を確認して承認することができます。関連オブジェクトタブには、パッケージの変更によって影響を受ける可能性のあるエクスポート定義、リスト、ビューが表示されます。
インポートパッケージを承認または却下するには、デフォルトで CDMS スーパーユーザおよび CDMS リードデータマネージャスタディロールに割り当てられているインポートの承認権限が必要です。
インポートの承認
インポートを承認するには:
- ソースへ移動します。
- インポートパッケージのリストを承認保留中でフィルタリングします。
-
パッケージ()メニューから、パッケージの詳細を表示 (View Package Details)を選択します。
- パッケージ詳細パネルで、差分をクリックして変更を表示します。
- 変更内容の確認
- パッケージの承認をクリックします。
- 任意: 理由を入力します。
- 承認をクリックします。
パッケージが承認され、処理のためにキューに入ります。
インポートの却下
インポートを却下するには:
- ソースへ移動します。
- インポートパッケージのリストを承認保留中でフィルタリングします。
-
パッケージ()メニューから、パッケージの詳細を表示 (View Package Details)を選択します。
- パッケージ詳細パネルで、差分をクリックして変更を表示します。
- 変更内容の確認
- パッケージの却下をクリックします。
- 任意: 理由を入力します。
- 却下をクリックします。
- パッケージの却下の確認ダイアログで、確認をクリックします。
関連オブジェクトの確認
インポートパッケージに関連付けられているオブジェクトは、パッケージ詳細パネルの関連オブジェクトタブで確認することができます。このタブには、パッケージの変更によって影響を受ける可能性のあるエクスポート定義、リスト、ビューが表示されます。
このタブにアクセスするには、パッケージ詳細パネルを開き、関連オブジェクトタブをクリックして開きます。
ワークベンチには、変更された各フォームのフォームピルに変更アイコン (オレンジの丸) のバッジが表示されます。
マニフェストファイルの「フォーム」属性にマッピングされているファイルについては、インポート済みのファイルで影響を受ける可能性のあるオブジェクトは、[関連オブジェクト] タブには表示されません。
インポートステータスを表示する
インポートパッケージのステータスは、インポート (Import) > パッケージ (Packages)で確認することができます。このページには、Vault EDCとサードパーティ製ツールの両方から行われた、すべてのインポートパッケージのステータスが一覧表示されます。このページからインポートパッケージや問題ログ (エラーと警告) をダウンロードすることができます。
ステータスの作成: インポートパッケージをインポート完了ステータスに移行するには、スタディ内のワークベンチユーザがリストを開く必要があります。開かれない場合、インポートのステータスは進行中のままとなります。試験が自動スワップ機能を有効化済みの場合は、これは必須ではありません。これは、すべての増分スタディとOpenEDCスタディに当てはまります。これらのスタディでは、自動スワップ機能がデフォルトで有効になっているためです。
制限付きデータアクセス権限のないユーザは、インポートパッケージログをダウンロードできますが、データファイルはダウンロードできません。データアクセスが制限されているユーザは、匿名化されたデータを含むパッケージをダウンロードできます。
フィルタリング
インポートステータスフィルタを使用して、リストを簡単にフィルタリングしてインポートが完了または失敗したものだけを表示することができます。失敗したインポートのみを表示するにはエラーをクリック、完了したインポートを表示するには完了をクリックします。
再処理中
ワークベンチは、インポートまたは最後の再処理から24時間後に、下記の回復可能な警告コードを含む、本番のサードパーティデータパッケージを自動的に再処理します。
- D-002: 施設が見つかりません
- D-003: 症例が見つかりません
- D-004: イベントが見つかりません
これらのコードが存在する場合、一次ソースとの一致が見つからなかったため、データファイル内の個々の行をインポートできなかったことを意味します。
ワークベンチでは、他の警告またはエラーコードを持つパッケージは再処理されません。これは、再処理では一次ソースから新しく入力されたデータが検索され、上記の警告のみが新しく入力されたデータによって解決できるためです。自動再処理は本番環境のみを対象としており、TST、TRNまたはVALでは対象とならないことに注意してください(上記の警告があっても対象ではありません)。
ワークベンチのインポートステータス
インポートパッケージが警告のみでインポートは可能である場合、ワークベンチは警告があることを示すためにオレンジ色でステータスを強調表示します。インポート完了後に問題ログをダウンロードして、警告内容を確認することができます。
| ステータス | 説明 |
|---|---|
| キュー処理済み | パッケージは処理キューにあります。このパッケージの前にも変更内容を含むパッケージが並んでおり、このパッケージは一時停止中のパッケージの承認または却下処理の待ち状態となります。 |
| 一時停止済み | CDB がマニフェストの変更を検出したため、パッケージが承認または却下されるまでインポート処理は一時停止状態となります。 |
| 承認済 | マニフェストの変更内容が承認されました。CDB がパッケージをインポートするようになります。 |
| 却下 | マニフェストの変更内容が却下されました。 |
| スキップされました | パッケージはスキップされ、インポートされませんでした。このパッケージが処理される前に、別のパッケージがソース用にインポートされました。このステータスは、サードパーティ製のパッケージにのみ適用されます。 |
| 進行中 | ワークベンチがエラーや警告を識別することなくこのパッケージのインポートプロセスが開始されました。 |
| 進行中 (警告あり) | インポート処理は進行中ですが、ワークベンチは警告を確認しました。 |
| エラー | インポートパッケージに 1 つ以上のエラーがあるため、インポートに失敗しました。問題ログをダウンロードしてエラーを確認してください。 |
| 完了 | ワークベンチはエラーや警告なしでパッケージを正常にインポートしました。 |
| 完了 (警告あり) | ワークベンチはパッケージを正常にインポートしましたが、1 つ以上の警告があります。問題ログをダウンロードして警告を確認してください。 |
| 未インポート | 処理が開始される前に同じソースの新しいパッケージがアップロードされたため、ワークベンチはこのパッケージをスキップしました。パッケージが未インポートステータスになった場合、ワークベンチは処理日を「置き換え済み」に書き換えます。 |
| 再処理進行中 | 別のソースから新しいパッケージがインポートされたため、ワークベンチによってこのパッケージの再処理が開始されました。 |
| 再処理完了 | ワークベンチはエラーや警告なしでこのパッケージの再処理を完了しました。 |
| 再処理完了 (警告あり) | ワークベンチはパッケージの再処理を完了しましたが、1 つ以上の警告があります。問題ログをダウンロードして警告を確認してください。 |
| 再処理エラー | インポートパッケージに 1 つ以上のエラーがあるため、再処理に失敗しました。問題ログをダウンロードしてエラーを確認してください。 |
インポートパッケージのダウンロード
インポートパッケージをダウンロードするには:
- 研究で、インポートへ移動します。
- ソースリストでソースを探します。
- パッケージをクリックして、ソースのパッケージページを開きます。
- リスト内のインポートパッケージへ移動します。
-
パッケージのリンクをクリックします。
- お好みのツールで ZIP フォルダからファイルを抽出して確認します。
ログのダウンロード
任意のインポートのインポートログ (CSV) と、失敗したインポートの問題ログ (CSV) のダウンロードが可能です。インポートログには、インポートジョブとワークベンチへのデータ取り込みに関する詳細が記載されています。
インポートログには以下の内容が記載されています:
- 変換開始時刻
- 変換完了時刻
- 変換の所要時間
- インポート開始時刻
- インポート完了時刻
- インポートの所要時間
インポートログをダウンロードするには:
- 研究で、インポートへ移動します。
- ソースリストでソースを探します。
- パッケージをクリックして、ソースのパッケージページを開きます。
- リスト内のインポートパッケージへ移動します。
- パッケージ () メニューから、ログのダウンロードを選択します。
問題ログ
問題ログには、パッケージのインポート中にワークベンチで発生したすべてのエラーと警告が記載されています。考えられるエラーと警告のリストについてはこちらを参照してください。
問題ログを確認するには:
- ソースのパッケージページに移動します。
- リスト内のインポートパッケージへ移動します。
- パッケージ () メニューから、パッケージの詳細を表示を選択します。
- パッケージの詳細パネルで、問題をクリックします。
- 任意: 問題ログパネルでダウンロード () をクリックしてログの CSV ファイルをダウンロードします。
アプリケーションで問題ログを最初に表示せずにダウンロードするには:
- ソースのパッケージページに移動します。
- リスト内のインポートパッケージへ移動します。
- パッケージ () メニューから、ログのダウンロードを選択します。
インポートデータの表示
増分取り込み: 増分取り込みでは、UI は最近インポートされたサードパーティデータパッケージ(経過時間に関係なく) と、過去 30 日以内にインポートされたすべてのサードパーティデータパッケージを表示します。
アップロード時に、ワークベンチはインポートパッケージ内の一意のファイルごとにフォームを作成します。ワークベンチは、そのフォームが Veeva EDC からのものであるか、サードパーティ製システムからインポートされたものであるかにかかわらず、研究内の一意のフォームごとにコアリストを自動的に生成します。
これらのコアリストのデフォルトの CQL クエリは以下のとおりです:
SELECT @HDR, * from source.filename 上記の研究所のインポートの例では、CDB は次のクエリを使用して、科学および血液学 (各 CSV ファイルに 1 つ) の 2 つのコアリストを作成します:
| 化学 |
|
| 血液学 |
|
定義
CDB は、インポートしたデータを CDB データワークベンチアプリケーション内で「フォーム」として定義するために、各 CSV ファイルのフォーム定義を作成します。これらのレコードでは、CSV ファイル名 (拡張子なし) を名前として使用します (例: 「hematology」)。また、CDB は、データ項目をフォーム内でグループ化するための項目グループ定義を作成します。CDB は、「ig_hematology」のように、CSVファイル名から拡張子を除き、先頭に「ig_」を付けた名前を付けます。
これらの定義 (form_name および ig_name) はどちらも、リスト内の列として表示されます。リストの CQL クエリを編集して、これらの列を非表示にすることができます。