导入包配置
可用性:临床数据库(CDB)仅对 CDB 许可证持有者提供。请联系 Veeva 服务代表了解详细信息。
在准备将第三方数据导入 CDB 时,主要活动之一是配置必须随数据一起导入的清单文件。此清单文件是一个 JSON(JavaScript 对象表示法)文件,CDB 用其配置指定源的导入行为,并描述数据属性和所需映射。要配置导入包,需要了解哪些属性需要配置以及如何正确配置这些属性。
为便于创建文件,CDB 提供了 CDB 清单生成器配置工具。CDB 清单生成器是一个逐步向导,可指导在用户友好的界面中完成所有清单文件配置选项。在清单生成器中,CDB 展示了每个导入选项,无需了解 JSON 即可进行设置。
在 CDB 清单生成器中,可以选择从头开始配置一个新文件,或导入一个现有文件进行修改。清单生成器包含四(4)个步骤:
- 数据包配置:定义数据包级属性,例如研究名称和数据源,以及如何将传入数据与 EDC 数据匹配。
- 添加数据文件:上传 CSV 文件以进行导入或创建加载数据的 CSV 文件模板。如果用户上传一个 CSV 文件,CDB 会读取标题行,并在文件配置步骤中自动添加这些值以供使用。
- 文件配置:定义所有文件特定的映射以及每列的数据类型和属性(例如长度、格式和精确率)。可用属性取决于所选的数据类型。默认情况下,CDB 将数据类型设置为文本,长度为“1500”。
- 摘要:预览所有配置的摘要,然后生成一个包含已配置清单文件的 ZIP 包和一个包含导入包中每个文件标题行的 CSV 文件。CDB 不会在清单生成器中保存任何配置,因此维护配置的唯一方法是生成 ZIP 包。
访问 CDB 清单生成器
用户无需登录 Vault 即可访问 CDB 清单生成器。CDB 清单生成器可通过直接链接访问。不同类型的 Vault(例如通用、受限和预发布版本)有不同的 URL。单击以下链接打开相应版本的清单生成器。
数据包配置
要创建清单文件,请执行以下操作:
- 导航到清单生成器(Manifest Builder)。
- 选择导入清单文件(Import Manifest File)(从现有 manifest.json 文件构建)或创建新清单文件(Create New Manifest File)(从头开始)。
- 单击下一步(Next)。
- 输入研究名称(Study Name)。此名称必须与 CDB 中的研究名称完全匹配。
- 输入数据源的名称。
- 如果使用的是 OpenEDC,请勾选主要数据源(Primary Source)复选框。
- 选择是(Yes)即启用严格导入(Enable Strict Import)。否则,请将此字段设置为否。启用严格导入后,CDB 仅导入清单文件中定义的列。不会导入文件中的所有其他列。
- 在匹配研究(Match Study On)选项中,选择名称(Name)或外部 ID(External ID)。这是 CDB 用于匹配研究的字段。
- 在匹配研究中心(Match Site On)选项中,选择名称(Name)或编号(Number)。这是 CDB 用于匹配研究中心的字段。
- 如果要在 EDC 中匹配事件,请选择是(Yes)。否则保持设置为否(No)。请参阅下文有关事件匹配的详细信息。如果选择了是(Yes):
- 在匹配事件(Match Events On)选项中,选择名称(Name)或外部 ID(External ID)。这是 CDB 用于将事件匹配到事件定义的字段。
- 如果要在 CDB 无法将导入的事件与现有事件匹配时创建新的事件,请保留当导入的事件无法与 EDC 事件匹配时在 CDB 中创建新事件(Create new Event in CDB when the Event from the Import cannot be matched to an EDC Event)的选项。否则,请取消勾选该复选框。
- 如果与 CSV 文件中的事件不匹配,请输入要用作事件默认值(Event Default)的事件名称。
- 单击下一步(Next)。
添加数据文件
如果已有包含数据的 CSV 文件,可以导入这些文件以便在配置清单时使用。否则,可以创建新的 CSV 文件(仅包含标题)以便后期添加数据。
连字符类型:连字符有两种不同类型,分别是“连字符减号”和“Unicode 连字符”。连字符减号是你按键盘上的 -(连字符)键通常输入的字符。在大多数现代字体中,这两种字符在视觉上是相同的。Veeva CDB 仅支持在数据导入时使用连字符减号。如果你导入的内容中包含 Unicode 连字符,导入将会失败。
导入数据文件
可以单击上传(Upload)区域,浏览并选择 CSV 文件,或将文件拖放到上传(Upload)区域。然后,单击下一步(Next)进入下一步骤。
添加新数据文件
- 单击添加新数据文件(Add New Data File)。
- 输入文件名称(File Name)。
-
要添加其他数据文件,请重复步骤 1 和 2。
- 要删除文件,请单击删除(Remove)()。
- 单击下一步(Next)。
添加代码列表
代码列表是一类数据收集项,研究中心用户需从定义的代码列表中进行选择。这些代码均已分配对应解码值。解码值是代码的易读标签。
你可配置导入文件,使其包含代码列表类型条目的数值和代码。
-
单击 + 新建编码列表(New Codelist)。这将打开新代码表(New Codelist)对话框。
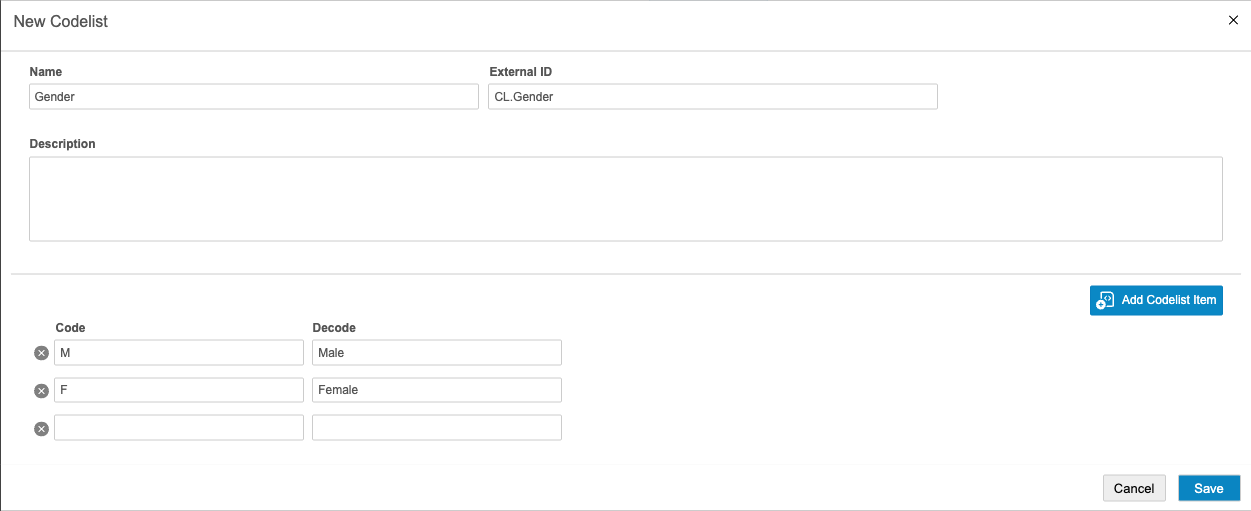
- 输入代码列表的名称。
- 可选:输入代码列表的外部 ID 和描述(Description)。
-
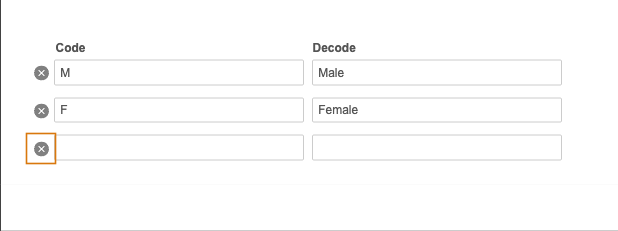
为每个代码列表条码输入代码和解码值。
-
如需添加更多代码列表条目行,请单击添加代码表项目(Add Codelist Item)新增一行。
-
要移除代码列表条目,请单击移除。
- 完成后,单击保存(Save)。
现在,你可在条目配置中引用此代码列表。

编辑代码列表
要编辑编码列表,请执行以下操作:
- 在清单生成器中进入代码列表步骤。
- 将鼠标悬停在要编辑的代码列表的名称上以显示操作()菜单。
-
从操作()菜单中,选择编辑。
- 进行更改。
- 完成后,单击保存(Save)。
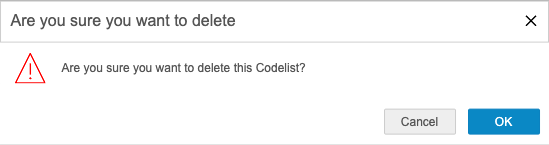
删除代码列表
删除代码列表的操作步骤如下:
- 在清单生成器中进入代码列表步骤。
- 将鼠标悬停在要删除的代码列表的名称上以显示操作()菜单。
-
从操作()菜单中,选择删除。
- 在确认对话框中,单击确定(OK)。
文件配置
每个 CSV 文件需经过四(4)个配置步骤:列映射、条目映射、重新排序列和唯一标识符。在文件选择(File Selection)标题中切换文件。
列映射
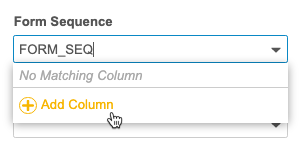
在步骤 3.1 中,可以映射不代表数据条目的列。要映射不存在的列,请开始在字段中输入所需的列标题,然后单击添加列(Add Column)。这会将列标题添加到下拉列表中。
要映射列,请执行以下操作:
- 选择研究(Study)列。
- 选择研究中心(Site)列。
- 选择受试者(Subject)列。
- 选择映射到列(Map to a column)以使用列值进行事件匹配,或选择将文件设置为特定事件默认值(Set file to specific Event default)以自动将导入的数据添加到事件默认值(Event Default)中。
- 选择事件(Event)列。
- 可选:输入表单标签。Workbench 将此标签用作表单 的标签。如果不输入表单标签,Workbench 将使用(由 CSV 文件名提供的)名称。
- 对于严格导入,可以选择与数据包级别相同(Same as package level),在整个数据包中使用相同的选择。否则,请选择是(Yes)启用数据文件的严格导入,或选择否(No)禁用。启用严格导入后,CDB 仅导入清单文件中定义的列。不会导入文件中的所有其他列。
- 要指定表单 和表单序列(如果文件包含跨越多个表单 的数据)的列,请勾选高级选项(Advanced Options)复选框。然后执行以下操作:
- 选择表单(Form)列。
- 选择表单序列(Form Sequence)列。
- 单击下一步(Next)。
列标题:请勿使用“研究名称”、“研究中心名称”或“受试者姓名”作为列标题,因为这可能会导致导出包生成期间出现错误。
条目映射
现在,可以为要为其导入数据的每个数据条目添加列。对于各条目,可以指定额外属性。
名称覆盖:默认情况下,Workbench 使用条目列(列标题)作为条目的名称。可以通过选中标题中的名称覆盖(Name Override)复选框并在每个条目的行中输入条目名称(Item Name)的值来覆盖此名称。
- 单击添加条目(Add Item)。
- 对于各条目列(Item Column),输入包含条目值的列的标题。
- 如果选中了名称覆盖复选框,请输入条目名称以用作条目的名称。
- 输入条目标签以用作条目的标签。
- 选择一种数据类型(Data Type)。根据所选的数据类型,CDB 允许配置适用的配置列(长度、最小值、最大值、精确率、格式和代码列表)。
- 输入或选择适用配置的值。
- 对每个条目重复步骤 1 至 4。
- 可选:配置盲态选项。请参见下面的详细信息。
- 要添加另一个条目,单击重复步骤 1 至 6。
- 完成后,单击下一步(Next)继续。
盲态选项
勾选盲态选项(Blinding Options)复选框后,工作台会在条目列表格中添加对此文件中的所有数据进行设盲(Blind all data on this file)复选框,以及盲态列(Blinded Column)和确定行盲态(Determines Row Blinding)列。
选择对此文件中的所有数据进行设盲(Blind all data on this file)即表示文件中的所有数据均受限制。要仅限制某些条目,请勾选盲态列(Blinded Column)复选框。
如果表单包含指示是否应对该行进行设盲的布尔类型条目,请为该条目勾选确定行盲态(Determines Row Blinding)复选框。
重新排序列
如果没有按首选顺序添加条目列,可以重新排序。使用置顶(Top)、上移(Up)、下移(Down)和置底(Bottom)按钮,或拖放列,以达到期望的列顺序。完成后,单击下一步(Next)。

唯一标识符
如果文件包含重复的表单或条目组,则需要进行额外配置。
如果文件中没有重复的表单或条目组,请为数据是否包含在受试者访视中重复的表单或条目组?(Does your data contain forms or item groups that repeat within a visit for a subject?)选择否(No),然后单击下一步(Next)。
如果有重复的表单或条目组,请执行以下步骤:
- 选择是,存在重复的表单或条目组(Yes, there are repeating forms or item groups)。
- 为定义分组的各列勾选组标识符(Group Identifier)复选框。
- 为各列勾选独特标识符(Distinct Identifier)复选框,以明确标识该组中的表单或条目组。
- 完成后,单击下一步(Next)。
如何删除文件
在步骤 3 中,可以随时从清单配置中删除文件。
要删除文件,请执行以下操作:
- 在文件选择标题中找到要删除的文件。
-
从文件(File)菜单()中,选择删除(Delete)。

- 在确认对话框中,单击删除选项卡(Delete Tab)。
审查摘要
摘要(Summary)页面显示每个数据文件的配置信息。在此处仔细查看配置。
在摘要中编辑配置
可以通过单击数据包配置(Package Configuration)面板中的编辑(Edit)来修改数据包级别详细信息。这将返回到步骤 1.2。
要修改文件级配置,请执行以下操作:
- 在文件选择标题中找到要删除的文件。
-
从文件(File)菜单()中,选择编辑(Edit)。
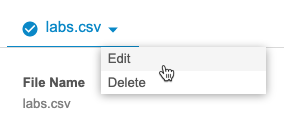
- 这将返回到所选文件的步骤 3.1。进行更改,然后在每个步骤中单击下一步(Next),直至返回到步骤 4。
生成摘要
查看配置后,可以生成导入包。
-
单击生成清单(Generate Manifest)。

- 将清单文件保存在所选位置。
- 如果是从头开始创建 CSV 文件,请不要将准备好的 CSV 文件导入到生成器中,请解压数据包并将数据添加到 CSV 文件中。
导入生成包
导入包包含所有数据后,将目录压缩为 ZIP 文件。然后,可以将其导入 Workbench。