제3자 데이터 가져오기
CDB를 사용하면 CDB Workbench 애플리케이션에서 정리 및 보고를 위해 제3자 시스템에서 데이터를 가져올 수 있습니다. 이 작업은 Veeva EDC의 대상자 사례집 외부에 존재하는 대상자 데이터(예: IRT 시스템의 대상자에 대한 데이터)를 가져오기 위한 것입니다.
가용성: 임상 데이터베이스(CDB)는 CDB 라이선스 보유자만 사용할 수 있습니다. 자세한 내용은 Veeva 서비스 담당자에게 문의하십시오.
필수 구성 요소
데이터를 CDB로 가져오려면 먼저 조직에서 다음 작업을 수행해야 합니다.
- 스터디, 스터디 국가 및 스터디 사이트를 생성합니다.
- Veeva EDC Studio에서 사례집 정의, 전체 디자인 정의 레코드 세트 및 스터디 일정을 생성하고 게시합니다. 여기에서 자세한 내용을 참조하십시오.
- 각 대상자에 대한 사례집 레코드를 생성합니다.
CDMS Lead Data Manager(CDMS 책임 데이터 매니저) 표준 스터디 역할을 보유한 사용자는 기본적으로 아래 설명된 작업을 수행할 수 있습니다. 조직에서 커스텀 역할을 사용하는 경우 역할에서 다음 권한을 부여해야 합니다.
| 유형(Type) | 권한 레이블 | 제어 |
|---|---|---|
| 표준 탭 | Workbench(Workbench) 탭 | Workbench 탭을 통해 데이터 Workbench 애플리케이션에 접근하고 이를 사용할 수 있는 권한 |
| 기능적 권한 | 가져오기 보기 | 가져오기 페이지에 접근할 수 있는 기능 |
| 기능적 권한 | API 접근권한 | Vault EDC API에 접근하고 이를 사용할 수 있는 기능(CDB를 사용하기 위해서도 이 권한 필요) |
| 기능적 권한 | 가져오기 승인 | 구성 변경 사항이 포함된 가져오기 패키지를 승인하거나 거부할 수 있는 기능 |
| 기능적 권한 | 가져오기 패키지 다운로드 | 가져오기 패키지를 다운로드할 수 있는 기능 |
| 기능적 권한 | 3PD 패키지 업로드 | CDB 패키지 로더를 통해 데이터를 가져오는 기능. |
가져올 데이터 준비
데이터를 일련의 CSV 파일로 Vault의 FTP 서버에 가져오거나, CDB 사용자 인터페이스 내에서 CDB 패키지 로더를 사용하여 업로드할 수 있습니다.
데이터를 가져오려면 먼저 임상 데이터가 나열된 CSV 파일과 데이터 및 CDB가 데이터를 처리하는 방법을 설명하는 매니페스트 파일(.json)을 생성해야 합니다. 그런 다음, CDB로 가져올 모든 파일이 포함된 ZIP 패키지(.zip)를 생성합니다.
매니페스트 빌더: CDB에는 파일을 쉽게 생성할 수 있도록 CDB 매니페스트 빌더가 포함되어 있습니다. CDB 매니페스트 빌더는 사용자 친화적인 인터페이스에서 모든 매니페스트 파일 구성 옵션을 안내하는 단계별 마법사입니다. CDB 매니페스트 빌더에서 CDB는 JSON을 이해하지 않고도 설정할 수 있는 모든 가져오기 옵션을 제공합니다.
데이터 CSV
EDC와 독립적인 스터디의 각 데이터 수집 폼에 대한 CSV를 생성합니다. 각 CSV에 대해 4개의 필수 열을 제공한 다음, 각 실행 데이터 아이템에 대한 열을 제공해야 합니다. 4개의 필수 열에 대해 각 CSV의 매니페스트 파일에서 해당 이름을 정의하는 한 원하는 대로 이름을 지정할 수 있습니다. 해당 열 이름은 대소문자를 구분하며 매니페스트 파일에 제공된 값과 정확히 일치해야 합니다.
스터디, 사이트, 대상자, 이벤트 및 시퀀스 열을 제외하고 CDB는 모든 열을 데이터 아이템으로 간주하여 데이터 아이템으로 가져옵니다. 리스팅당 아이템 열은 410개로 제한됩니다.
| 열 | 설명 | 매니페스트 파일 키 |
|---|---|---|
| 스터디 |
이 열에 스터디 이름을 제공합니다. 스터디에서는 스터디 이름( "Studyname"을 이 열의 헤더로 사용하면 내보내기 패키지를 생성하는 동안 오류가 발생할 수 있으므로 사용하지 마십시오.
|
study |
| 사이트(Site) |
이 열에는 (Veeva EDC의 사이트 레코드에서) 사이트 이름(사이트 번호)을 제공합니다. "Sitename"을 이 열의 헤더로 사용하면 내보내기 패키지를 생성하는 동안 오류가 발생할 수 있으므로 사용하지 마십시오.
매니페스트 파일에서 사이트 열을 정의하지 않고 CSV 파일에서 열을 제외하면 Workbench에서 대상자 열을 기준으로 일치시킬 수 있습니다. Workbench는 해당 작업을 수행할 때 대상자 ID가 스터디 레벨에서 고유할 것으로 예상합니다. |
site |
| 대상자 |
이 열에는 (Veeva EDC의 대상자 레코드 이름 필드에서) 대상자의 대상자 ID를 제공합니다. "Subjectname"을 이 열의 헤더로 사용하면 내보내기 패키지를 생성하는 동안 오류가 발생할 수 있으므로 사용하지 마십시오.
|
subject |
| 이벤트 | 이 열에는 데이터 행과 연결된 이벤트(방문)를 제공합니다. 매니페스트 파일의 edc_matching 구성에 따라 EDC 이벤트 정의의 이름 또는 외부 ID, EDC 이벤트의 이벤트 날짜를 사용하거나 이 열의 이벤트를 사용하여 Workbench에서 EDC 일정과 별도로 이벤트를 생성하도록 할 수 있습니다. 또한 매니페스트 파일의 모든 행에 대해 기본 이벤트를 설정하고 이 열을 완전히 제외하여 모든 행을 해당 이벤트에 할당할 수 있습니다. 아래에서 이벤트 일치에 대해 자세히 알아보십시오. | event |
| 폼 *선택 사항 |
이 열에는 (Veeva EDC의 폼 정의 레코드 이름에서) 데이터 행과 연결된 폼을 제공합니다. 이 열은 단일 CSV에서 여러 폼의 데이터를 가져오는 경우에만 필요합니다. 이 열을 포함하지 않으면 Workbench는 각 데이터 행이 단일 폼의 발생 아이템이라고 가정합니다. 아래에서 폼 매핑에 대해 자세히 알아보십시오. |
form |
| 폼 시퀀스 *반복 폼의 경우 필수, 반복되지 않는 폼의 경우 선택 사항 |
폼이 반복되는 경우 폼의 시퀀스 번호. 반복 폼은 단일 대상자의 단일 이벤트 동안 동일한 데이터를 두 번 이상 수집하는 것을 나타냅니다. 그런 다음, 시퀀스 번호는 데이터 행을 고유하게 식별합니다. 대상자 및 이벤트에 대한 행(폼)이 두 개 이상 있는 경우 Workbench는 폼이 반복된다고 가정하고 이 열을 사용하여 시퀀스 번호를 설정합니다. 이 열은 폼이 반복되는 경우 필수이지만 폼이 반복되지 않는 경우에는 선택 사항입니다. 이 경우 Workbench는 기본적으로 각 행의 시퀀스 번호를 "1"로 설정합니다. 반복 폼에 이 열을 포함하지 않으면 Workbench는 기본적으로 시퀀스 번호를 "1"로 설정하여 동일한 대상자/사이트/폼/폼 시퀀스 번호 식별자가 있는 행이 생성되므로 데카르트 곱이 생성될 수 있습니다. 20R1 릴리스에서는 "sequence"의 이름이 "formsequence"로 바뀌었습니다. 20R2 릴리스(2020년 8월)까지 "sequence"를 사용하여 데이터를 계속 가져올 수 있습니다. |
formsequence |
| 아이템 그룹 *선택 사항 |
이 열에는 (Veeva EDC의 아이템 그룹 정의 레코드 이름에서) 그 뒤에 있는 아이템 열과 연결된 아이템 그룹을 제공합니다. 이 열은 여러 아이템 그룹이 있는 폼 데이터를 가져오는 경우에만 필요합니다. 이 열을 포함하지 않으면 Workbench는 데이터 행의 모든 아이템이 단일 아이템 그룹에 있다고 가정합니다. 아래에서 아이템 그룹 매핑에 대해 자세히 알아보십시오. |
itemgroup |
| 아이템 그룹 시퀀스 *반복 아이템 그룹의 경우 필수, 반복되지 않는 아이템 그룹의 경우 선택 사항 |
아이템 그룹이 반복되는 경우 아이템 그룹의 시퀀스 번호. 반복 아이템 그룹은 단일 대상자의 단일 폼 동안 동일한 데이터를 두 번 이상 수집하는 것을 나타냅니다. 그런 다음, 시퀀스 번호는 데이터 행을 고유하게 식별합니다. 대상자 및 이벤트에 대한 폼 행에 아이템 세트가 두 개 이상 있는 경우 Workbench는 폼이 반복된다고 가정하고 이 열을 사용하여 시퀀스 번호를 설정합니다. 반복 아이템 그룹에 이 열을 포함하지 않으면 Workbench는 기본적으로 시퀀스 번호를 "1"로 설정하여 동일한 대상자/사이트/폼/폼 시퀀스/아이템 그룹/아이템 그룹 시퀀스 번호 식별자가 있는 행이 생성되므로 데카르트 곱이 생성될 수 있습니다. 반복되지 않는 아이템 그룹의 경우 이 열은 선택 사항이므로 비워 두거나 반복 아이템 그룹이 없는 경우 제공하지 않을 수 있습니다. 이 경우 Workbench는 기본적으로 각 행의 시퀀스 번호를 "1"로 설정합니다. |
itemgroupsequence |
| 행 ID *선택 사항 21R2 및 이전 |
값이 결합될 때 Workbench에서 행을 고유하게 식별하는 데 사용할 수 있는 열 목록을 제공합니다. 이 작업은 시퀀스를 식별할 숫자 키가 없는 경우에 유용합니다. 예를 들어 실험실 데이터를 가져올 때 스터디, 대상자 및 실험실 테스트를 사용하여 행을 고유하게 식별할 수 있습니다. rowid 열 매핑을 포함하면 Workbench는 모든 시퀀스 값을 무시하고 자동으로 시퀀스를 "1"로 설정합니다. 생략하면 Workbench는 기본 열 배열을 사용하여 행(study, subject, event, form, formsequence)을 식별합니다.rowid에 대한 단일 열 목록을 제공하는 것은 여전히 지원되지만 향후 릴리스에서는 제거될 예정입니다. 대신 groupid와 distinctid를 rowid에 대한 열 목록으로 정의하십시오. 아래 행을 참조하십시오. |
rowid |
| 행 ID *선택 사항 21R3 및 이후 |
그룹 ID: 21R3 릴리스 이전에 생성된 데이터 가져오기에 존재하는 레거시 필드입니다. 21R3 릴리스 이후의 데이터 가져오기에서는 고유 ID를 사용해야 합니다. 그룹 ID를 사용하면 고유 ID와 같은 폼 또는 아이템 그룹 시퀀스 번호가 자동으로 증가하지 않기 때문에 데이터 무결성 이슈가 발생합니다. 예를 들어 데이터가 폼 또는 아이템 그룹 시퀀스 번호를 명시적으로 매핑하지 않는 경우 기본값은 1입니다. 이로 인해 스터디, 사이트, 대상자 및 이벤트, 폼, 폼 시퀀스 번호, 아이템 그룹 및 아이템 그룹 시퀀스 번호의 값이 정확히 동일한 여러 레코드를 가져오게 될 수 있습니다. 결과적으로 CQL에서 이를 중복 레코드로 간주하면서 리스팅 결과의 일관성이 떨어질 수 있습니다. 고유 ID: 값이 결합될 때 Workbench에서 그룹 컨텍스트 내에서 레코드를 고유하게 식별하는 데 사용할 수 있는 열 목록을 제공합니다( 행 외부 ID: EDC의 외부 ID와 같은 외부 ID를 데이터 행에 할당할 수 있습니다. 이에 따라 제3자 데이터에 대한 쿼리 원본을 식별할 수 있습니다. |
groupid, distinctid 및 rowexternalid가 있는 rowid |
하이픈 유형: 하이픈에는 "하이픈 마이너스" 및 "유니코드 하이픈"과 같이 두 가지 유형이 있습니다. 하이픈 마이너스는 일반적으로 키보드에서 -(하이픈) 키를 눌러 얻을 수 있는 키입니다. 대부분의 최신 글꼴에서 이러한 문자는 시각적으로 동일합니다. Veeva CDB는 데이터 불러오기에서 하이픈 마이너스 사용만 지원합니다. 유니코드 하이픈을 포함하면 가져오기가 실패합니다.
다음은 예시 CSV 파일입니다.
| STUDY_ID | SITE | SUBJECT_ID | VISIT | INITIALS | DOB | GENDER | RACE |
|---|---|---|---|---|---|---|---|
| S.Deetoza | 101 | 101-1001 | 선별 | CDA | 03-27-1991 | F | 히스패닉 |
이 예시에는 다음과 같은 열 매핑이 있습니다.
- 스터디: STUDY_ID
- 사이트: SITE
- 대상자: SUBJECT_ID
- 이벤트: VISIT
INITIALS, DOB, GENDER 및 RACE 열은 모두 데이터 아이템입니다.
매니페스트 파일
매니페스트 파일은 CDB에 대한 스터디 및 원본을 제공하고 ZIP에 있는 파일을 나열하며 각 파일에 대해 필요한 데이터 포인트에 매핑되는 열을 나열합니다.
원본은 패키지 내용을 식별할 수 있는 커스텀 값입니다. 이 값은 Workbench의 원본 필드에 저장되므로 CQL을 통해 Workbench에서 이 패키지의 데이터를 식별하는 데 사용할 수 있습니다. 원본 값은 스터디 내에서 고유해야 합니다.
스터디에서는 스터디 이름(study__v) 레코드를 제공합니다. 스터디에서는 스터디 이름(study__v) 레코드를 제공합니다. 스터디 이름에 공백 문자가 포함되어 있으면 매니페스트 파일에서 공백이 있는 값을 사용해야 하지만 데이터 파일에서 공백을 밑줄(_)로 바꿔야 합니다.
원본에서는 데이터 원본을 지정합니다. 시스템은 이 원본을 가져온 모든 데이터에 적용합니다. 그런 다음, 파일 이름(확장자 포함) 및 열 매핑을 포함한 각 CSV 파일을 배열로 "data" 값으로 나열합니다.
가져오기 파일의 각 데이터 아이템에 대한 구성 메타데이터를 포함하도록 선택할 수 있습니다. 세부 사항은 아래에서 참조하십시오.
이 파일을 "manifest.json"으로 저장합니다.
Workbench는 정확한 파일 이름(대소문자 구분) 및 확장자를 가진 매니페스트 파일만 허용합니다.
예시 매니페스트: 단일 폼
다음은 eCOA에서 설문조사 폼이 포함된 패키지를 가져오는 Deetoza 스터디용 예시 매니페스트 파일입니다.
{ "study": "Deetoza", "source": "eCOA", "data": [ { "filename": "Survey.csv", "study": "protocol_id", "site": "site_id", "subject": "patient", "event": "visit_name" } ] } 예시 매니페스트: 여러 폼
다음은 실험실 공급업체에서 화학 및 혈액학 폼이 포함된 패키지를 가져오는 Deetoza 스터디용 예시 매니페스트 파일입니다.
{ "study": "Deetoza", "source": "lab", "data": [ { "filename": "Chemistry.csv", "study": "STUDY_ID", "site": "SITE_ID", "subject": "SUBJECT_ID", "event": "VISIT", "formsequence": "LAB_SEQ" }, { "filename": "Hematology.csv", "study": "STUDY_ID", "site": "SITE_ID", "subject": "SUBJECT_ID", "event": "VISIT", "formsequence": "LAB_SEQ" } ] } 행 ID 매핑을 사용하고 단일 CSV 파일을 사용하여 화학 및 혈액학 실험실 데이터를 가져올 수도 있습니다. 해당 CSV 파일에서 실험실 테스트 세트 열을 사용하여 행에 화학 또는 혈액학을 나타낼 수 있습니다.
{ "study": "Deetoza", "source": "lab", "data": [ { "filename": "Labs.csv", "study": "STUDY_ID", "site": "SITE_ID", "subject": "SUBJECT_ID", "event": "VISIT" } ] } 폼 레이블 오버라이드
제3자 데이터 소스를 가져올 때 form_label 키를 매핑하여 폼에 대한 레이블을 정의할 수 있으며, 이는 리스팅에서 CQL로 참조할 수 있습니다.
form_label 키를 사용하는 방법에는 두 가지가 있으며, 매니페스트에서 폼 키가 사용되는지 여부에 따라 예상 입력이 다릅니다.
폼 키가 매니페스트에서 데이터 파일의 열에 매핑하는 데 사용되고 form_label 키도 사용되는 경우, form_label 키에 대한 입력은 폼 레이블을 찾을 수 있는 데이터 파일의 열도 나타냅니다. form_label 키는 form 키와 함께 데이터 배열의 일부입니다.
{ "study": "Deetoza", "source": "lab", "data": [ { "filename": "hematology_lpanel.csv", "study": "STUDY_ID", "site": "SITE_ID", "subject": "SUBJECT_ID", "event": "VISIT", "formsequence": "LAB_SEQ", "form": "FORM_NAME_COLUMN" "form_label": "FORM_LABEL_COLUMN" } ] } form 키가 사용되지 않고 form_label 키가 매니페스트에서 사용되는 경우, form_label 키에 대해 예상되는 입력은 문자열이며 여기에서 문자열 값은 사용할 폼 레이블과 동일합니다. 폼에 대한 레이블을 정의하려면 form_label 레이블을 데이터 배열에 추가하십시오.
{ "study": "Deetoza", "source": "lab", "data": [ { "filename": "hematology_lpanel.csv", "study": "STUDY_ID", "site": "SITE_ID", "subject": "SUBJECT_ID", "event": "VISIT", "formsequence": "LAB_SEQ", "form_label": "Hematology" } ] } 아이템의 이름 및 레이블을 오버라이드하려면 이름 및 레이블 속성을 아이템의 구성에 추가하십시오. 세부 사항은 아래에서 참조하십시오.
선택 사항: 이벤트 일치
기본적으로 Workbench는 폼의 CSV 파일에 있는 이벤트를 Veeva EDC의 일치하는 이벤트 정의 레코드 이름과 일치시킵니다. Workbench에서 이벤트 정의의 외부 ID를 기준으로 이벤트를 일치시키도록 선택할 수도 있습니다. 또한 매니페스트 파일에서 기본 이벤트를 정의하고 모든 행을 해당 이벤트에 자동으로 할당할 수 있습니다. 데이터가 EDC에 예약된 이벤트 외부에서 수집된 경우 EDC 이벤트에 매핑하지 않도록 선택하고 Workbench에서 필요에 따라 가져오기 패키지의 이벤트와 일치하는 이벤트를 생성하도록 할 수 있습니다.
이벤트가 반복 이벤트 그룹 내에 있는 경우 Workbench는 이벤트 정의의 외부 ID를 사용하고 일치시키기 위해 시퀀스 번호를 추가합니다. 시퀀스 번호는 파일의 각 고유 이벤트에 대해 증가합니다. 이벤트가 두 개 이상의 이벤트 그룹에서 재사용되는 경우 반복으로 간주되지 않습니다. 대신 Workbench는 해당 이벤트를 EDC 일정에서 첫 번째로 일치하는 이벤트와 일치시킵니다.
기본 동작
매니페스트 파일에 이벤트 일치 구성을 포함하지 않으면 다음 기본값이 적용됩니다.
- Workbench는 이벤트 정의 이름을 사용하여 일치시킵니다.
- Workbench는 기존 EDC 이벤트와 일치시키려고 시도합니다. EDC에 일치하는 이벤트가 없는 경우 Workbench는 새 이벤트를 생성합니다.
이 기본 동작은 아래 매니페스트 구성과 동일합니다.
{ "study": "Deetoza", "source": "Labs", "edc_matching": { "event": { "target": ["name"], "generate": true } } } 이름 일치(기본값)
매니페스트 파일에 edc_matching을 포함하지 않으면 Workbench는 이벤트 정의 이름을 사용하여 자동으로 일치시킵니다. 매니페스트 파일에서 이름 기반 일괄 처리를 지정할 수도 있습니다.
{ "study": "Deetoza", "source": "Labs", "edc_matching": { "event": { "target": ["name"] } } } 외부 ID 일치
이벤트 정의의 외부 ID(이전의 OID)를 일치시키려면 edc_matching을 포함하고 이벤트 대상을 external_id로 설정해야 합니다. 아래 예시 발췌를 참조하십시오.
{ "study": "Deetoza", "source": "Labs", "edc_matching": { "event": { "target": ["external_id"] } } } 기본 이벤트 설정
CSV에 이벤트를 나열하는 대신 매니페스트 파일에서 이벤트를 기본 이벤트로 선택할 수 있습니다. 그러면 Workbench에서 해당 CSV 파일의 모든 행을 해당 이벤트에 자동으로 할당합니다. 이 작업은 default 키로 제어됩니다. default에 이벤트 정의 이름을 사용합니다. 특정 데이터 파일에 대한 기본값을 설정하거나 패키지 레벨에서 기본값을 설정할 수 있습니다.
예시: 패키지 레벨 기본 이벤트
{ "study": "Deetoza", "source": "lab", "edc_matching": { "event": { "default": "treatment_visit" } }, "data": [ { "filename": "Labs.csv", "study": "STUDY_ID", "site": "SITE_ID", "subject": "SUBJECT_ID", "event": "VISIT", "rowid": ["LAB_TEST_SET", "LAB_TEST_SEQ"] } ] } 예시: 파일 레벨 기본 이벤트
{ "study": "Deetoza", "source": "Labs", "edc_matching": { "event": { "default": "treatment_visit", } } } 일치하지 않는 이벤트 처리
기본적으로 Workbench에서 이름 또는 외부 ID를 기준으로 이벤트를 EDC의 이벤트와 일치시킬 수 없는 경우 원본과 관련된 비EDC 이벤트에 대해 새 이벤트를 생성합니다. 이러한 새 이벤트는 전체 Workbench 헤더 이벤트 레코드(@HDR.Event에서 CQL을 통해 액세스 가능)의 일부가 됩니다. 이 작업은 generate 키로 제어됩니다. 기본 동작의 매니페스트 구성은 generate: true입니다. 데이터가 EDC 이벤트 일정 외부에서 수집된 경우 generate를 false로 설정하여 EDC 이벤트와 일치시키지 않도록 선택할 수 있습니다. generate를 false로 설정하면 Workbench에서 새 이벤트 정의를 생성하지 않습니다. 대신 EDC 이벤트와 일치하지 않는 모든 행에 대해서는 가져오기가 실패합니다.
예시: 외부 ID 일치 및 일치하지 않는 이벤트 무시
{ "study": "Deetoza", "source": "Labs", "edc_matching": { "event": { "target": ["external_id"], "generate": false } } } 데이터가 완전히 EDC 일정 외부에서 수집된 경우 EDC 이벤트와 일치시키지 않고 Workbench에서 각 이벤트에 대해 새 이벤트를 생성하도록 선택할 수 있습니다. 이렇게 하려면 아래 예시와 같이 event를 false로 설정합니다.
{ "study": "Deetoza", "source": "Labs", "edc_matching": { "event": false } } 선택 사항: 폼 및 아이템 그룹 매핑
Workbench에서 데이터 세트 내의 반복 폼 및 아이템 그룹을 해석하는 방법을 정의하는 것을 포함하여 CSV의 행을 다른 폼 및 아이템 그룹에 매핑하도록 선택할 수 있습니다. 이렇게 하면 Workbench에서 단일 CSV를 단일 폼 및 단일 아이템 그룹 대신 여러 폼 및 아이템 그룹으로 변환할 수 있습니다.
예를 들어 실험실 폼에는 각 실험실 테스트 범주당 하나의 아이템 그룹으로 여러 아이템 그룹이 포함될 수 있습니다. itemgroup 열을 사용하여 행의 데이터 아이템이 속한 아이템 그룹을 나타낼 수 있습니다. Workbench는 행의 매핑되지 않은 모든 열을 items로 처리합니다. Workbench는 행의 지정된 아이템 그룹 내에서 해당 아이템을 가져옵니다. 아이템 구성에서 해당 열에 대한 추가 메타데이터를 지정할 수 있습니다. 세부 사항은 아래에서 참조하십시오.
아래 표를 참조하면 Workbench가 다양한 폼 및 아이템 그룹 구성 시나리오에서 데이터를 처리하는 방법을 이해할 수 있습니다.
| 폼 정의됨 | 아이템 그룹 정의됨 | 결과 |
|---|---|---|
| 아니요(No) | 아니요(No) | Workbench는 각 행을 단일 폼의 한 발생 항목으로 처리합니다. |
| 예(Yes) | 아니요(No) | Workbench는 각 행을 다른 폼으로 처리하여 form 열에서 폼을 식별합니다. form 열의 각 고유 값은 다른 폼으로 처리됩니다. |
| 아니요(No) | 예(Yes) | Workbench는 각 행을 아이템 그룹(itemgroup 열에 정의됨)의 인스턴스로 처리하고 해당 행을 대상자 및 폼별로 그룹화합니다. 각 아이템 그룹을 반복 아이템 그룹으로 처리하려면 itemgroupsequence 열을 사용합니다. |
| 예(Yes) | 예(Yes) | Workbench는 대상자, form 및 itemgroup별로 행을 그룹화합니다. form 열의 각 고유 값은 다른 폼으로 처리되며 itemgroup 열의 각 고유 값은 아이템 그룹입니다. |
예시 매니페스트: 여러 폼
아래 예시에서 "Labs.csv" 파일에는 여러 폼이 포함되어 있습니다. 해당 폼은 "Labs.csv" 파일의 form 열에서 식별됩니다.
{ "study": "Deetoza", "source": "lab", "data": [ { "filename": "Labs.csv", "study": "protocol_id", "site": "site_id", "subject": "subject_id", "event": "visit", "form": "form" } ] } 
예시 매니페스트: 여러 아이템 그룹
아래 예시 매니페스트 파일에서 실험실 폼에는 여러 아이템 그룹이 있습니다. 해당 폼은 "Labs.csv" 파일의 lab_category 열에서 식별됩니다.
{ "study": "Deetoza", "source": "lab", "data": [ { "filename": "Labs.csv", "study": "protocol_id", "site": "site_id", "subject": "subject_id", "event": "visit", "item_group": "lab_category" } ] } 
선택 사항: 코드 목록 구성
코드 목록 유형 아이템에서 참조하도록 코드 목록을 구성할 수 있습니다. 코드 목록은 사용자가 데이터를 입력할 때 선택할 수 있는 코드 및 디코드 쌍 세트입니다.
각 코드 목록에 대해 name, external_id(선택 사항) 및 codelist_data를 제공하게 됩니다. codelist_data는 code 및 decode 쌍을 허용합니다.
"codelists": [ { "name": "SEX", "external_id": "SEX", "codelist_data": [ { "code": "M", "decode": "Male" }, { "code": "F", "decode": "Female" } ] } ] 선택 사항: 아이템 구성
매니페스트 파일 내에 아이템 메타데이터를 포함하여 CDB Workbench가 데이터 아이템을 처리하는 방법을 알릴 수 있습니다. 각 아이템에 대한 데이터 형식을 지정할 수 있을 뿐만 아니라 데이터 형식 선택에 따라 추가 속성도 지정할 수 있습니다.
아이템 구성을 생략하면 CDB Workbench에서 모든 아이템을 텍스트로 처리합니다.
단순 구성 및 고급 구성 비교
"config" 오브젝트 아이템에는 단순 및 고급의 두 가지 구성 형식이 있습니다. 단순 구성의 경우 아이템의 데이터 형식만 지정합니다. 아이템 속성은 기본값을 사용합니다. 고급 구성의 경우 데이터 형식과 속성을 지정합니다.
"items" { "Weight": "float" }"items" { "Weight": { "type": "float", "precision": 2 } }이름 및 레이블 정의
아이템의 구성에서 아이템의 이름 및 레이블을 정의할 수 있습니다. 이러한 키는 모든 아이템 데이터 형식으로 매핑하는 데 사용할 수 있습니다.
레이블을 제공하려면 label 키를 매핑하십시오. 생략하면 이 값은 기본적으로 아이템의 이름과 일치합니다. 기본적으로 Workbench는 열 헤더를 아이템 이름으로 사용합니다. 이를 오버라이드하려면 매니페스트 파일에서 name_override 키를 매핑하면 됩니다. 이름에는 영숫자, 대시 및 밑줄만 포함할 수 있습니다. 공백은 허용되지 않습니다.
"items": { "REQ_NUM": { "type": "text", "length": 10, "name_override": "REQUESTION_NUM", "label": "Requisition Number" }, "EVENTTYP": { "type": "text", "length": 10, "label": "Event Type" }, "COL_DATE": { "type": "date", "format": "ddMMMyyyy", "name_override": "COLLECTION_DATE", "label": "Collection Date" }, "COL_TIME": { "type": "time", "format": "HH:mm", "label": "Collection Time" } } 데이터 형식별로 사용 가능한 속성
각 데이터 형식에 사용할 수 있는 다양한 구성 속성이 있습니다.
| Data Type | 예시 구성 | 속성 | 속성 설명 |
|---|---|---|---|
| 텍스트 |
|
길이 | 허용되는 문자 수. 기본 길이는 1,500자입니다. |
| 정수 |
|
Min | 허용되는 최소(가장 낮은)값. 기본값은 -2,147,483,647입니다. |
| Max | 허용되는 최대(가장 높은)값. 기본값은 2,147,483,647입니다. | ||
| 부동 소수점 |
|
길이 |
소수점의 왼쪽과 오른쪽 모두에 허용되는 최대 자릿수 최대값의 자릿수가 이 속성보다 많은 경우 Workbench는 해당 숫자를 대신 사용합니다. |
| Precision |
허용되는 소수 자릿수. 기본값은 5입니다. 최대값의 소수 자릿수가 이 속성보다 많은 경우 Workbench는 해당 숫자를 대신 사용합니다. |
||
| Min | 허용되는 최소(가장 낮은)값. 기본값은 -4,294,967,295입니다. | ||
| Max | 허용되는 최대(가장 높은)값. 기본값은 4,294,967,295입니다. | ||
| 날짜 |
|
형식 |
날짜 값을 구문 분석하는 데 사용할 형식 패턴. 아래에서 지원되는 날짜 형식 목록을 참조하십시오. 기본값은 "yyyy-MM-dd"입니다. |
| 날짜 시간 |
|
형식 |
날짜 시간 값을 구문 분석하는 데 사용할 형식 패턴. 아래에서 지원되는 날짜 및 시간 형식 목록을 참조하십시오. 기본값은 "yyyy-MM-dd HH:mm"입니다. |
| 시간 |
|
형식 |
시간 값을 구문 분석하는 데 사용할 형식 패턴. 아래에서 지원되는 시간 형식 목록을 참조하십시오. 기본값은 "HH:mm"입니다. |
| 불린 |
|
해당 없음 | 불린 데이터 형식에는 구성 속성이 없습니다. Workbench는 불린 값에 대해 "true"/"false", "yes"/"no" 및 "1"/"0"을 허용합니다. |
| codelist |
|
코드 목록 | 이 아이템이 사용하는 코드 목록을 지정합니다. 코드 목록은 사용자가 데이터를 입력할 때 선택할 수 있는 정의된 코드 및 디코드 쌍(코드 목록 아이템) 목록입니다. 코드 목록을 정의하는 방법은 위를 참조하십시오. |
지원되는 날짜 및 시간 형식 패턴
아래 나열된 형식 패턴은 날짜, 날짜 시간 및 시간 아이템에 사용할 수 있습니다. 날짜 시간 아이템의 경우 날짜 및 시간 패턴을 결합합니다(예: "yy-MM-dd HH:mm"). 날짜에 시간 형식 패턴을 사용하거나 그 반대의 경우 오류(D-012)가 발생하면서 가져오기에 실패합니다.
| 형식 패턴 | 예시 | 설명 |
|---|---|---|
| dd MM yy | 02 18 20 | 2자리 일, 2자리 월, 2자리 연도, 공백( ) 구분 기호 사용 |
| dd MM yyyy | 02 18 2020 | 2자리 일, 2자리 월, 전체 연도, 공백( ) 구분 기호 사용 |
| dd MMM yyyy | 02 Feb 2020 | 2자리 일, 축약형 월(텍스트), 전체 연도, 공백( ) 구분 기호 사용 |
| dd-MM-yy | 18-02-20 | 2자리 일, 2자리 월, 2자리 연도, 대시(-) 구분 기호 사용 |
| dd-MM-yyyy | 18-02-2020 | 2자리 일, 2자리 월, 전체 연도, 대시(-) 구분 기호 사용 |
| dd-MMM-yyyy | 18-Feb-2020 | 2자리 일, 축약형 월(텍스트), 전체 연도, 대시(-) 구분 기호 사용 |
| dd-MMM-yyyy HH:mm:ss | 18-Feb-2020 12:10:50 | 2자리 일, 축약형 월(텍스트), 전체 연도, 대시(-) 구분 기호 사용, 시간(초 포함) |
| dd/MMM/yy | 18/Feb/20 | 2자리 일, 축약형 월(텍스트), 2자리 연도, 슬래시(/) 구분 기호 사용 |
| dd-MMM-yy | 18-Feb-20 | 2자리 일, 축약형 월(텍스트), 2자리 연도, 대시(-) 구분 기호 사용 |
| ddMMMyy | 18Feb20 | 2자리 일, 축약형 월(텍스트), 2자리 연도(구분 기호 없음) |
| dd MMM yy | 18 Feb 20 | 2자리 일, 축약형 월(텍스트), 2자리 연도, 공백( ) 구분 기호 사용 |
| dd.MM.yy | 18.02.20 | 2자리 일, 2자리 월, 2자리 연도, 마침표(.) 구분 기호 사용 |
| dd.MM.yyyy | 18.02.2020 | 2자리 일, 2자리 월, 전체 연도, 마침표(.) 구분 기호 사용 |
| dd/MM/yy | 18/02/20 | 2자리 일, 2자리 월, 2자리 연도, 슬래시(/) 구분 기호 사용 |
| dd/MM/yyyy | 18/02/2020 | 2자리 일, 2자리 월, 전체 연도, 슬래시(/) 구분 기호 사용 |
| ddMMMyyyy | 18Feb2020 | 2자리 일, 축약형 월(텍스트), 전체 연도(구분 기호 없음) |
| ddMMyy | 180220 | 2자리 일, 2자리 월, 2자리 연도(구분 기호 없음) |
| ddMMyyyy | 18022020 | 2자리 일, 2자리 월, 전체 연도(구분 기호 없음) |
| MM/dd/yy | 02/18/20 | 2자리 월, 2자리 일, 2자리 연도, 슬래시(/) 구분 기호 사용 |
| MM/dd/yyyy | 02/18/2020 | 2자리 월, 2자리 일, 전체 연도, 슬래시(/) 구분 기호 사용 |
| MMddyy | 021820 | 2자리 월, 2자리 일, 2자리 연도(구분 기호 없음) |
| MMddyyyy | 02182020 | 2자리 월, 2자리 일, 전체 연도(구분 기호 없음) |
| MMM dd yyyy | Feb 18 2020 | 축약형 월(텍스트), 2자리 일, 전체 연도, 공백( ) 구분 기호 사용 |
| MMM/dd/yyyy | Feb/18/2020 | 전체 월(텍스트), 2자리 일, 4자리 연도, 슬래시(/) 구분 기호 사용 |
| MMMddyyyy | Feb182020 | 전체 월(텍스트), 2자리 일, 4자리 연도(구분 기호 없음) |
| yy-MM-dd | 20-02-18 | 2자리 연도, 2자리 월, 2자리 일, 대시(-) 구분 기호 사용 |
| yy/MM/dd | 20/02/18 | 2자리 연도, 2자리 월, 2자리 일, 슬래시(/) 구분 기호 사용 |
| yyyy MM dd | 2020 02 18 | 전체 연도, 2자리 월, 2자리 일, 공백( )을 구분 기호로 사용 |
| yyyy-MM-dd | 2020-02-18 | 전체 연도, 2자리 월, 2자리 일, 대시(-)를 구분 기호로 사용 |
| yyyy-MM-dd'T'HH:mm | 2020-02-18T12:10 | 전체 연도, 2자리 월, 2자리 일, 대시(-)를 구분 기호로 사용, 시간 |
| yyyy.dd.MM | 2020.18.02 | 전체 연도, 2자리 일, 2자리 월, 마침표(.)를 구분 기호로 사용 |
| yyyy.MM.dd | 2020.02.18 | 전체 연도, 2자리 월, 2자리 일, 마침표(.)를 구분 기호로 사용 |
| yyyy/MM/dd | 2020/02/18 | 전체 연도, 2자리 월, 2자리 일, 슬래시(/) 구분 기호 사용 |
| yyyyMMdd | 20200218 | 전체 연도, 2자리 월, 2자리 일(구분 기호 없음) |
| yyyyMMdd'T'HH:mm | 2020218T12:10 | 전체 연도, 2자리 월, 2자리 일(구분 기호 없음), 시간 |
| dd/MM/yyyy HH:mm | 18/02/2020 18:30 | 2자리 일, 2자리 월, 4자리 연도, 슬래시(/)를 구분 기호로 사용, 24시간제 |
| MM/dd/yyyy HH:mm | 02/18/2020 18:30 | 2자리 월, 2자리 일, 4자리 연도, 슬래시(/)를 구분 기호로 사용, 24시간제 |
| yyyy-MM-dd'T'HH:mm:ss+HH:mm | 2020-02-18T18:30:22+00:00 | 4자리 연도, 2자리 월, 2자리 일, 대시(-)를 구분 기호로 사용, 24시간제(초 포함), UTC의 시간 오프셋(+HH:mm) 포함 참고: 매니페스트 파일은 T를 작은따옴표(')로 묶어야 하지만 CSV 파일에는 이러한 작은따옴표를 포함하지 마십시오. |
| yyyy-MM-dd'T'HH:mm:ssZ | 2020-02-18T18:30:22Z | 4자리 연도, 2자리 월, 2자리 일, 대시(-)를 구분 기호로 사용, UTC 시간 기준 24시간제(초 포함) 참고: 매니페스트 파일은 T를 작은따옴표(')로 묶어야 하지만 CSV 파일에는 이러한 작은따옴표를 포함하지 마십시오. |
| yyyyMMdd'T'HH:mm:ssZ | 20200218T18:30:22Z | 4자리 연도, 2자리 월, 2자리 일, UTC 시간 기준 24시간제(초 포함) 참고: 매니페스트 파일은 T를 작은따옴표(')로 묶어야 하지만 CSV 파일에는 이러한 작은따옴표를 포함하지 마십시오. |
| yyy-MM-dd'T'HH:mm:ss | 2020-2-18T12:10:41 | 전체 연도, 2자리 월, 2자리 일, 대시(-)를 구분 기호로 사용, 시간(초 포함) 참고: 매니페스트 파일은 T를 작은따옴표(')로 묶어야 하지만 CSV 파일에는 이러한 작은따옴표를 포함하지 마십시오. |
| ddMMyyyy'T'HH:mm:ss | 10122024T16:15:30 | 2자리 일, 2자리 월, 4자리 연도, 구분 기호 없음, 24시간제 참고: 매니페스트 파일은 T를 작은따옴표(')로 묶어야 하지만 CSV 파일에는 이러한 작은따옴표를 포함하지 마십시오. |
| yyyyMMdd HH:mm:ss | 20241210 16:15:30 | 4자리 연도, 2자리 월, 2자리 일, 구분 기호 없음, 24시간제(초 포함) |
| MM/dd/yyyy HH:mm:ss | 12/10/2024 16:15:30 | 2자리 월, 2자리 일, 4자리 연도, 슬래시(/) 구분 기호, 24시간제(초 포함) |
| yyyy-MM-dd'T'HH:mm:ss | 2024-12-10T16:15:30 | 4자리 연도, 2자리 월, 2자리 일, 대시(-) 구분 기호, 24시간제 참고: 매니페스트 파일은 T를 작은따옴표(')로 묶어야 하지만 CSV 파일에는 이러한 작은따옴표를 포함하지 마십시오. |
| HH:mm | 18:30 | 24시간제 |
| HH:mm:ss | 18:30:15 | 24시간제(초 포함) |
예시 패키지: 단일 폼, 아이템 메타데이터
다음은 Verteo Pharma의 무작위 배정 공급업체의 예시 가져오기 패키지로, 아이템 메타데이터가 있는 무작위 배정 폼이 포함되어 있습니다.
manifest.json:
{ "study": "Cholecap", "source": "IRT", "data": [{ "filename": "Randomization.csv", "study": "protocol_id", "site": "site_id", "subject": "patient", "event": "visit_name", "items": { "randomization_number": { "type": "integer", "length": "14" }, "date_of_randomization": { "type": "date", "format": "yyyy-MM-dd" } } }] } Randomization.csv:
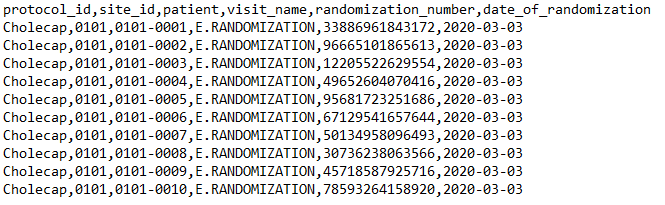
엄격한 가져오기
매니페스트 파일의 엄격한 가져오기 매개 변수를 사용하면 데이터 CSV 파일의 모든 아이템 열 대신 매니페스트에 정의된 아이템으로만 데이터 수집을 제한할 수 있습니다. 이 옵션을 전체 패키지 또는 개별 파일에 적용할 수 있습니다. 파일 레벨 설정은 패키지 레벨 설정을 오버라이드합니다.
"strict_import" 매개 변수는 true 또는 false를 허용합니다. 엄격한 가져오기를 활성화하려면 이 매개 변수를 true로 설정합니다.
선택 사항: 데이터 제한(눈가림)
아이템, 행, 리스팅 데이터 파일 및 원본 레벨에서 데이터를 제한(눈가림)하여 제한된 데이터에 접근할 수 있는 권한이 없는 사용자에게 데이터를 숨길 수 있습니다. 예를 들어 스터디에서 스터디 약물을 사용하는 대상자에 대해서만 특정 실험실을 지시할 수 있습니다. 대상자가 어떤 실험실에 있는지 알게 되면 대상자의 눈가림이 해제됩니다. 눈가림된 사용자가 해당 대상자를 식별하지 못하도록 이 정보를 제한할 수 있습니다.
| 제한 레벨 | 매니페스트 파일 구성 |
|---|---|
| 아이템 |
|
| 폼 레코드 *가져오는 특정 폼 레코드에 대한 데이터를 제한합니다. 해당 행의 눈가림 여부를 설명하는 열을 사용합니다. |
|
| 리스팅 데이터 파일 |
|
| 원본 패키지 |
|
제한된 데이터에 접근할 수 있는 사용자(일반적으로 책임 데이터 매니저)의 경우 제한된 데이터는 무제한 데이터와 동일한 방식으로 작동합니다. 눈가림된 사용자(제한된 데이터 접근권한 권한이 없는 사용자)의 경우 가져온 제한된 데이터에 다음 동작 규칙이 적용됩니다.
- 아이템(열)이 제한된 경우:
- CQL 프로젝션은 제한된 아이템의 열을 반환하지 않습니다.
- CQL 프로젝션은 제한된 아이템을 참조하는 파생 열을 반환하지 않습니다.
- 눈가림된 사용자가 CQL 문에서 제한된 아이템을 참조하는 경우 CQL은 여전히 열을 반환하지 않습니다.
SHOW및DESCRIBE는 제한된 아이템을 반환하지 않습니다.
- 행이 제한된 경우:
- 결과 세트는 폼 또는 아이템 그룹의 행을 반환하지 않습니다.
- 리스팅 파일(csv)이 제한된 경우:
- 기본
@HDR열은 리스팅에 포함되지만 아이템 열은 포함되지 않습니다.
- 기본
- 원본(패키지)이 제한된 경우:
- CQL은 어떤 리스팅에서도 제한된 원본의 아이템 또는 열 결과를 반환하지 않습니다.
- CDB는 원본 내의 모든 아이템 정의, 아이템 그룹 정의 및 폼 정의를 제한됨으로 표시합니다.
- 모든 데이터 행은 제한됨으로 표시됩니다.
- 기본 @HDR 열은 코어 리스팅에 계속 표시됩니다.
ZIP 패키지
매니페스트 파일과 CSV 생성이 완료되면 파일을 함께 압축합니다. 해당 파일을 압축하기 전에 폴더에 넣지 마십시오. 이 ZIP 폴더의 이름을 원하는 대로 지정할 수 있습니다. 그러나 "Study-Name_Source_datetime.zip"과 같이 고유 식별자를 사용하여 이름을 지정하는 것이 좋습니다. ZIP 폴더에 폴더를 포함하지 마십시오. 모든 CSV 파일과 매니페스트 파일은 동일한 레벨에 있어야 합니다.
Vault의 FTP 서버 액세스
도메인의 각 Vault에는 자체 FTP 스테이징 서버가 있습니다. FTP 서버는 Vault에 업로드하거나 Vault에서 추출하는 파일을 위한 임시 저장 영역입니다.
서버 URL
각 스테이징 서버의 URL은 해당 Vault와 동일합니다(예: veepharm.veevavault.com).
FTP 서버에 접근하는 방법
자주 사용하는 FTP 클라이언트 또는 명령줄을 통해 스테이징 서버에 접근할 수 있습니다.
FTP 클라이언트에서 다음 설정 사용:
- 프로토콜(Protocol): FTP(파일 전송 프로토콜)
- 암호화(Encryption): 명시적 FTPS(FTP over TLS)가 필요합니다. 이는 보안 요구 사항입니다. 네트워크 인프라는 FTPS 트래픽을 지원해야 합니다.
- 포트(Port): 일반적으로 추가할 필요가 없으며 기본적으로 포트 21로 설정됩니다.
- 호스트(Host): {DNS}.veevavault.com. 예를 들면 "veepharm"은 veepharm.veevavault.com의 DNS입니다.
- 사용자(User): {DNS}.veevavault.com+{USERNAME}. 로그인할 때 사용하는 것과 동일한 사용자 이름을 사용합니다. 예: veepharm.veevavault.com+tchung@veepharm.com.
- 암호(Password): 이 Vault의 로그인 암호. 표준 로그인에 사용된 것과 동일한 암호입니다.
- 로그인 유형(Login Type): 기본
- 전송 파일 유형(Transfer File Type): 이진으로 파일 전송
대용량 파일을 업로드하는 데 문제가 있는 경우 FTP 클라이언트 시간 초과 설정을 180초로 늘립니다.
프록시 또는 방화벽에서 원격 검증을 활성화한 경우 네트워크의 컴퓨터에서 Veeva FTP 서버로의 FTP 트래픽이 거부될 수 있습니다. 가능한 경우 IT 부서와 협력하여 원격 확인을 사용하지 않도록 설정하십시오. 비활성화할 수 없는 경우 Veeva 지원에 문의하십시오.
FTP 디렉터리 구조
사용자 디렉터리 내부에는 "workbench" 디렉터리가 있습니다. 여기에서 제3자 데이터를 업로드할 수 있습니다. CDB는 여기에 넣은 모든 파일을 자동으로 인식합니다.
CDB는 가져온 파일을 "workbench/_processed"로 이동합니다. 세부 사항은 아래에서 참조하십시오.
데이터 가져오기
FTP 클라이언트 또는 CDB 사용자 인터페이스 내의 CDB 패키지 로더를 사용하여 두 가지 방법으로 Workbench로 데이터를 가져올 수 있습니다.
FTP 클라이언트를 사용하여 가져오기
FTP 클라이언트를 사용하여 데이터를 가져오려면 선택한 FTP 클라이언트를 사용하여 ZIP 파일을 FTP 스테이징 서버의 "workbench" 디렉터리에 업로드합니다. ZIP을 FTP 스테이징 서버에 업로드하면 CDB에서 ZIP을 가져와서 데이터를 변환합니다.
CDB 패키지 로더를 사용하여 가져오기
Workbench 사용자 인터페이스를 사용하여 데이터를 가져오려면 CDB 패키지 로더를 통해 ZIP 파일을 업로드합니다.
CDB 패키지 로더에 접근하는 방법은 다음과 같습니다.
-
상단 탐색 모음에서 데이터 패키지 업로드(Upload Data Packages)를 클릭하거나 탐색 창에서 패키지 로더(Package Loader)를 클릭합니다.
-
ZIP 파일을 끌어다 놓기(Drag and drop) 영역으로 끌어다 놓습니다. 이 영역을 클릭하여 파일을 찾아보고 업로드할 수도 있습니다.

- 업로드된 파일이 선택한 패키지(Selected Packages) 아래에 나타납니다. 파일을 제거하려면 X를 클릭합니다.
- 업로드(Upload)를 클릭합니다.
한 번에 최대 10개의 패키지를 업로드할 수 있으며, 각 파일은 200MB를 초과할 수 없습니다. 파일이 이 제한을 초과하면 오류 메시지가 나타나고 시스템에서 업로드를 차단합니다.
가져오기가 완료되면 Workbench에서 사용자와 원본을 구독한 다른 모든 사용자에게 이메일 알림을 보냅니다. 패키지를 재처리하여 이전 로드가 변경되는 경우 Workbench는 사용자와 해당 원본을 구독한 사용자에게도 알림을 보냅니다.
가져오기 완료
가져오기가 완료되면 다음 작업이 수행됩니다.
- CDB는 모든 정의 레코드와 해당 레코드 간의 관계를 생성합니다.
- CDB는 가져온 모든 레코드의 매니페스트에 제공된 값으로 원본 필드를 자동으로 설정하여 데이터 원본을 고유하게 식별합니다. (Veeva EDC에서 가져온 모든 폼에서는 이 값이 자동으로 "EDC"로 설정됩니다. 제3자 데이터 소스 및 OpenEDC 기본 소스는 "EDC"라는 명칭을 사용할 수 없습니다.)
- CDB는 가져오기 패키지의 각 고유 폼에 대한 코어 리스팅을 생성합니다. 세부 사항은 아래에서 참조하십시오.
- CDB는 가져오기 ZIP 파일을 다음에서 이동합니다.
- 가져오기에 FTP 클라이언트를 사용한 경우 "workbench"에서 "workbench/_processed/{study}/{source}"로 이동합니다. 또한 CDB는 파일 이름에 가져온 날짜와 시간을 추가합니다.
- 가져오기에 패키지 로더를 사용한 경우 Vault 파일 스테이징에서 "workbench/_processed/{study}/{source}"로 이동합니다.
이제 Workbench에서 리스팅을 볼 수 있습니다. 현재 릴리스에서는 Workbench에 새 리스팅이 즉시 표시되지 않습니다. 먼저 스터디의 리스팅(Listings) 페이지로 이동하여 다른 코어 리스팅을 클릭해서 연 다음, 리스팅(Listings) 페이지로 돌아갑니다. 그러면 새 데이터 리스팅이 목록에 표시됩니다. 이제 리스팅 중 하나의 이름(Name)을 클릭하여 열 수 있습니다.
가져오기 실패
가져오기 실패 시:
- CDB는 가져오기 시도 날짜와 시간을 ZIP 파일의 파일 이름에 추가합니다.
- CDB는 가져오기 ZIP 파일을 다음에서 이동합니다.
- 가져오기에 FTP 클라이언트를 사용한 경우 "workbench"에서 "workbench/_error"로 이동합니다.
- 가져오기에 CDB 패키지 로더를 사용한 경우 Vault 파일 스테이징에서 "workbench/_error"로 이동합니다.
- CDB는 오류 로그("<import datetime>_<package name>_errors.csv")를 생성합니다.
가능한 오류 목록과 해결 방법을 참조하십시오.
오류 제한: 가져오기 로그는 최대 10,000개의 오류 및 경고만 캡처하며, 이 임계값을 충족하면 기록이 중지됩니다.
소스 보기 및 패키지 가져오기
가져오기(Import) 페이지에서 스터디의 소스 및 연관된 가져오기 패키지를 검토할 수 있습니다.
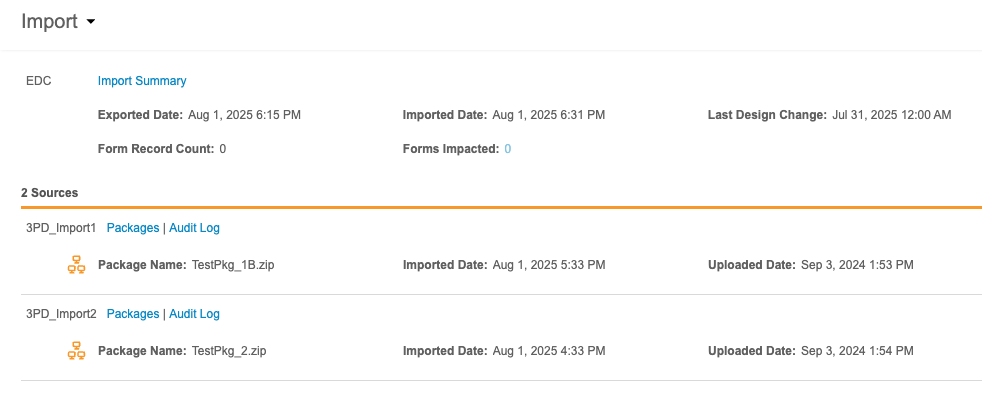
이 페이지 상단에는 기본 소스에 대한 가져오기 정보가 있으며, 해당 소스가 Veeva EDC인지 제3자 EDC 시스템인지 명시되어 있습니다. 이 헤더에는 다음 정보가 포함됩니다.
- 가져오기 요약을 다운로드할 수 있는 링크
- 내보낸 날짜(EDC 시스템에서 이 데이터를 내보낸 날짜)
- 가져온 날짜(Workbench로 이 데이터를 가져온 날짜)
- 마지막 디자인 변경(EDC 시스템의 마지막 스터디 디자인/임상시험계획서 변경 날짜 및 시간)
- 폼 레코드 수(새로 가져온 패키지의 영향을 받는 폼 레코드 수)
- 영향을 받는 폼(새로 가져온 패키지의 영향을 받는 폼 수)
가져오기 요약은 Veeva EDC의 모든 증분 로드를 요약합니다. 여기에는 일별로 다음 정보가 포함됩니다.
- 날짜
- 증분 패키지 수(이 날에 가져온 증분 패키지 수)
- 전체 패키지 수(이 날에 가져온 전체 패키지 수)
- 오류(가져오는 동안 오류가 발생했는지 여부를 "예" 또는 "아니요"로 표시)
가져오기 날짜 범위를 기준으로 이 목록을 필터링할 수 있습니다.
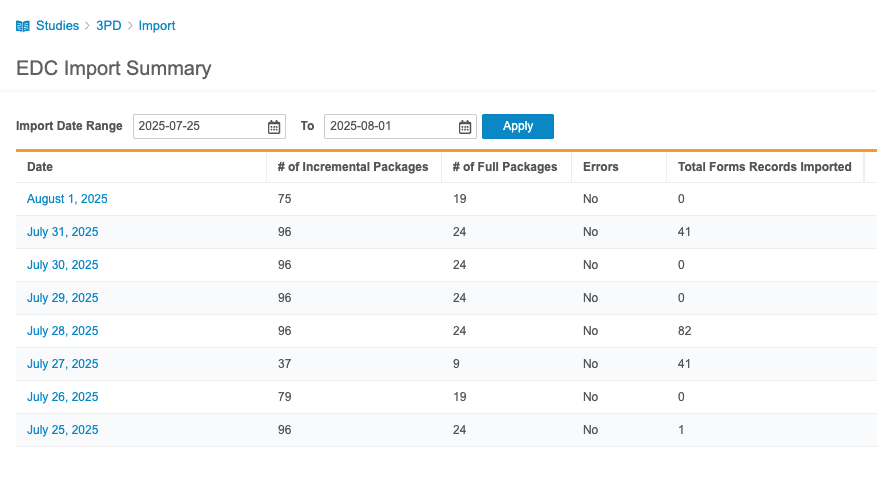
날짜를 클릭하여 해당 날짜의 모든 패키지를 검토합니다. Workbench에서는 각 가져오기 패키지에 대해 다음 정보를 포함합니다.
- EDC 내보낸 날짜
- 업로드 날짜
- 가져온 날짜
- 전체 로드(true/false 확인란)
- 가져온 총 폼 레코드
- 상태(Status)
- 세부 정보
변경 사항이 있는 가져오기 검토 및 승인
CDB로 가져오는 데이터가 승인된 형식 및 구조에서 변경되지 않도록 하기 위해 CDB는 각 제3자 원본에 대해 로드마다 패키지 구성의 변경 사항을 감지합니다.
시스템이 패키지, 파일 또는 눈가림 레벨에서 구성 변경 사항이나 CSV 파일 구조의 변경 사항을 감지하면 CDB는 가져오기 프로세스를 일시 중지합니다. 패키지는 처리되지 않으며 승인 권한이 있는 사용자가 패키지를 승인하거나 거부할 때까지 일시 중지됨 상태로 전환됩니다. 사용자가 패키지를 승인하면 CDB는 승인 이유를 기록하고 데이터 패키지를 가져옵니다. 패키지가 승인되면 CDB는 이메일을 통해 승인된 변경 사항을 구독자에게 알립니다. CDB는 모든 관련 리스팅 및 보기에 변경 표시기를 표시합니다. 사용자는 이 표시기를 해제하고 모든 리스팅 또는 보기에 대한 폼 변경 로그를 다운로드할 수 있습니다. 사용자가 패키지를 거부하는 경우 CDB는 거부 이유를 기록하고 패키지를 거부됨으로 표시한 후 가져오지 않음 상태를 할당합니다. 그런 다음, CDB는 원본에 대해 마지막으로 가져온 데이터 패키지로 되돌립니다.
패키지가 일시 중지됨 상태이면 동일한 원본에 대해 업로드된 다른 모든 패키지가 대기열에 들어가고 일시 중지된 패키지가 승인되거나 거부될 때까지 대기합니다. 일시 중지된 패키지가 승인되거나 거부되면 CDB는 처리를 위해 마지막으로 대기 중인 패키지로 건너뜁니다. 마지막으로 일시 중지된 패키지와 대기열의 마지막 패키지 사이에 있는 모든 패키지는 처리되지 않습니다. 예를 들어 "패키지 1"이 업로드되고 일시 중지된 후 "패키지 1"이 여전히 일시 중지됨 상태일 때 패키지 2~5가 업로드된 경우 "패키지 1"이 승인되거나 거부되면 CDB는 "패키지 5"로 건너뛰고 패키지 2~4는 처리되지 않은 상태로 둡니다.
새 원본에 업로드된 첫 번째 패키지의 경우 CDB는 자동으로 일시 중지됨 상태를 적용하며 사용자는 해당 원본의 데이터가 시스템에 표시되기 전에 첫 번째 패키지를 승인하거나 거부해야 합니다.
승인이 필요한 패키지의 경우 이제 Workbench에 차이점(Differences) 및 연결된 오브젝트(Associated Objects) 탭이 있는 패키지 세부 사항(Package Detail) 패널이 포함됩니다. 차이점(Differences) 탭에는 현재 패키지와 이전 패키지 간의 매니페스트 변경 사항이 표시됩니다. 사용자는 승인하는 변경 사항의 이전 및 현재 값을 검토할 수 있습니다. 연결된 오브젝트(Associated Objects) 탭에는 패키지의 변경 사항이 잠재적으로 영향을 미칠 수 있는 내보내기 정의, 리스팅 및 보기가 표시됩니다.
가져오기 패키지를 승인하거나 거부하려면 가져오기 승인 권한이 필요하며, 이 권한은 기본적으로 표준 CDMS Super User(CDMS 슈퍼 사용자) 및 CDMS Lead Data Manager(CDMS 책임 데이터 매니저) 스터디 역할에 할당됩니다.
가져오기 승인
가져오기를 승인하는 방법은 다음과 같습니다.
- 소스(Source)로 이동합니다.
- 승인 보류 중(Pending Approvals)을 기준으로 가져오기 패키지 목록을 필터링합니다.
-
패키지(Package) 메뉴()에서 패키지 세부 사항 보기(View Package Details)를 선택합니다.
- 패키지 세부 사항(Package Details) 패널에서 차이점(Differences)을 클릭하여 변경 사항을 표시합니다.
- 변경 사항을 검토합니다.
- 패키지 승인(Approve Package)을 클릭합니다.
- 선택 사항: 이유(Reason)를 입력합니다.
- 승인을 클릭합니다.
패키지가 승인되고 이제 처리를 위해 대기열에 들어갑니다.
가져오기 거부
가져오기를 거부하는 방법은 다음과 같습니다.
- 소스(Source)로 이동합니다.
- 승인 보류 중(Pending Approvals)을 기준으로 가져오기 패키지 목록을 필터링합니다.
-
패키지(Package) 메뉴()에서 패키지 세부 사항 보기(View Package Details)를 선택합니다.
- 패키지 세부 사항(Package Details) 패널에서 차이점(Differences)을 클릭하여 변경 사항을 표시합니다.
- 변경 사항을 검토합니다.
- 패키지 거부(Reject Package)를 클릭합니다.
- 선택 사항: 이유(Reason)를 입력합니다.
- 거부를 클릭합니다.
- 패키지 거부(Reject Package) 확인 대화 상자에서 확인(Confirm)을 클릭합니다.
연결된 오브젝트 검토
패키지 세부 사항(Package Details) 패널의 연결된 오브젝트(Associated Objects) 탭에서 가져오기 패키지의 연결된 오브젝트를 검토할 수 있습니다. 이 탭에는 패키지의 변경 사항이 잠재적으로 영향을 미칠 수 있는 내보내기 정의, 리스팅 및 보기가 나열됩니다.
이 탭에 접근하려면 패키지 세부 사항(Package Details) 패널을 열고 연결된 오브젝트(Associated Objects) 탭을 클릭하여 엽니다.
Workbench는 변경된 각 폼의 폼 필에 변경 아이콘(주황색 원) 배지를 표시합니다.
매니페스트 파일의 "form" 특성에 매핑된 파일의 경우 연결된 오브젝트(Associated Objects) 탭에는 가져온 파일에서 잠재적으로 영향을 받을 수 있는 오브젝트가 표시되지 않습니다.
가져오기 상태 보기
가져오기(Import) > 패키지(Packages)에서 가져오기 패키지 상태를 확인할 수 있습니다. 이 페이지에는 Vault EDC 및 제3자 툴의 모든 가져오기 패키지 상태가 나열되어 있습니다. 이 페이지에서 가져오기 패키지 및 문제 로그(오류 및 경고)를 다운로드할 수도 있습니다.
완료 상태: 가져오기 패키지가 가져오기 완료 상태로 이동하려면 스터디의 Workbench 사용자가 리스팅을 열어야 합니다. 그렇지 않으면 가져오기가 진행 중 상태로 유지됩니다. 스터디에 자동 전환 기능이 활성화되어 있으면 이 작업이 필요하지 않습니다. 모든 증분 및 OpenEDC 스터디가 여기에 해당하는데, 해당 스터디에서는 기본적으로 자동 전환 기능이 활성화되어 있기 때문입니다.
제한된 데이터 접근권한 권한이 없는 사용자는 가져오기 패키지 로그를 다운로드할 수 있지만 데이터 파일은 다운로드할 수 없습니다. 제한된 데이터 접근권한이 있는 사용자는 눈가림된 데이터가 포함된 패키지를 다운로드할 수 있습니다.
필터링
가져오기 상태 필터를 사용하여 완료되거나 실패한 가져오기만 표시하도록 목록을 쉽게 필터링할 수 있습니다. 오류(Error)를 클릭하여 실패한 가져오기만 표시하거나 완료(Complete)를 클릭하여 완료된 가져오기를 표시합니다.
재처리
Workbench는 가져오기 또는 마지막 재처리 시간으로부터 24시간 후에 아래에 나열된 복구 가능한 경고 코드가 포함된 프로덕션 제3자 데이터 패키지를 자동으로 재처리합니다.
- D-002: 사이트를 찾을 수 없음
- D-003: 대상자를 찾을 수 없음
- D-004: 이벤트를 찾을 수 없음
이러한 코드가 있으면 데이터 파일의 개별 행을 가져올 수 없다는 의미입니다. 원인은 기본 소스와 일치하는 아이템을 찾을 수 없기 때문입니다.
Workbench는 다른 경고 또는 오류 코드가 있는 패키지는 재처리하지 않는데, 재처리 시 기본 소스에서 새로 입력된 데이터를 찾기 때문입니다. 새로 입력한 데이터를 통해 해결할 수 있는 경고는 위 세 가지뿐입니다. 자동 재처리는 프로덕션 환경에만 해당되며, TST, TRN 또는 VAL에는 적용되지 않습니다(위 경고가 있는 경우에도 동일).
Workbench 가져오기 상태
가져오기 패키지가 경고가 포함된 상태로만 가져올 수 있는 경우 Workbench는 상태를 주황색으로 강조 표시하여 경고가 있음을 나타냅니다. 가져오기가 완료되면 문제 로그를 다운로드하여 경고를 검토할 수 있습니다.
| 상태(Status) | 설명 |
|---|---|
| 대기열에 포함 | 패키지가 처리 대기열에 있습니다. 이 패키지 앞에는 변경 사항도 포함된 패키지가 있으며, 이 패키지는 일시 중지된 패키지가 승인되거나 거부되기를 기다리고 있습니다. |
| 일시 중지됨 | CDB가 매니페스트에서 변경 사항을 감지했으므로 사용자가 패키지를 승인하거나 거부할 때까지 가져오기가 일시 중지됩니다. |
| 승인됨 | 매니페스트의 변경 사항이 승인되었습니다. 이제 CDB가 패키지를 가져옵니다. |
| 거부됨(Rejected) | 매니페스트의 변경 사항이 거부되었습니다. |
| 건너뜀(Skipped) | 패키지를 건너뛰었고 가져오지 않았습니다. 이 패키지가 처리되기 전에 원본에 대해 다른 패키지를 가져왔습니다. 이 상태는 제3자 패키지에만 적용될 수 있습니다. |
| 진행 중 | 이 패키지에 대한 가져오기 프로세스가 시작되었으며 Workbench에서 오류나 경고를 식별하지 못했습니다. |
| 진행 중(경고 포함)(In Progress (with warnings)) | 가져오기 프로세스가 진행 중이지만 Workbench에서 경고를 확인했습니다. |
| 오류(Error) | 가져오기 패키지에 하나 이상의 오류가 있어 가져오기에 실패했습니다. 문제 로그를 다운로드하여 오류를 검토하십시오. |
| 완료(Complete) | Workbench에서 오류나 경고 없이 패키지를 성공적으로 가져왔습니다. |
| 완료(경고 포함)(Complete (with warnings)) | Workbench에서 패키지를 성공적으로 가져왔지만 하나 이상의 경고가 있습니다. 문제 로그를 다운로드하여 경고를 검토하십시오. |
| 가져오지 않음 | 처리가 시작되기 전에 동일한 원본에 대한 최신 패키지가 업로드되었기 때문에 Workbench에서 이 패키지를 건너뛰었습니다. 패키지가 가져오지 않음 상태가 되면 Workbench는 처리 날짜도 "교체됨"으로 바꿉니다. |
| 재처리 진행 중 | 다른 원본에서 새 패키지를 가져왔기 때문에 Workbench에서 이 패키지를 재처리하기 시작했습니다. |
| 재처리 완료 | Workbench에서 오류나 경고 없이 이 패키지 재처리를 완료했습니다. |
| 재처리 완료(경고 포함) | Workbench에서 이 패키지 재처리를 완료했지만 하나 이상의 경고가 있습니다. 문제 로그를 다운로드하여 경고를 검토하십시오. |
| 재처리 오류 | 가져오기 패키지에 하나 이상의 오류가 있어 재처리에 실패했습니다. 문제 로그를 다운로드하여 오류를 검토하십시오. |
가져오기 패키지 다운로드
가져오기 패키지를 다운로드하는 방법은 다음과 같습니다.
- 스터디의 가져오기로 이동합니다.
- 원본 목록에서 원본을 찾습니다.
- 패키지를 클릭하여 원본의 패키지 페이지를 엽니다.
- 리스팅에서 가져오기 패키지를 찾습니다.
-
패키지(Package) 링크를 클릭합니다.
- ZIP 폴더에서 파일을 추출하고 선택한 툴에서 봅니다.
로그 다운로드
가져오기에 대한 가져오기 로그(CSV)와 실패한 가져오기에 대한 문제 로그(CSV)를 다운로드할 수 있습니다. 가져오기 로그에는 가져오기 작업 및 Workbench로의 데이터 수집에 대한 세부 정보가 나열됩니다.
가져오기 로그에는 다음이 나열됩니다.
- 변환 시작 시간
- 변환 완료 시간
- 변환 기간
- 가져오기 시작 시간
- 가져오기 완료 시간
- 가져오기 기간
가져오기 로그를 다운로드하는 방법은 다음과 같습니다.
- 스터디의 가져오기로 이동합니다.
- 원본 목록에서 원본을 찾습니다.
- 패키지를 클릭하여 원본의 패키지 페이지를 엽니다.
- 리스팅에서 가져오기 패키지를 찾습니다.
- 패키지() 메뉴에서 로그 다운로드(Download Logs)를 선택합니다.
문제 로그
문제 로그에는 패키지를 가져오는 동안 Workbench에서 발생한 모든 오류 및 경고가 나열됩니다. 여기에서 가능한 오류 및 경고 목록을 참조하십시오.
문제 로그를 보는 방법은 다음과 같습니다.
- 원본의 패키지 페이지로 이동합니다.
- 리스팅에서 가져오기 패키지를 찾습니다.
- 패키지() 메뉴에서 패키지 세부 사항 보기(View Package Details)를 선택합니다.
- 패키지 세부 사항 패널에서 문제(Issues)를 클릭합니다.
- 선택 사항: 문제 로그(Issue Log) 패널에서 다운로드()를 클릭하여 로그의 CSV를 다운로드합니다.
애플리케이션에서 먼저 문제 로그를 보지 않고 다운로드하는 방법은 다음과 같습니다.
- 원본의 패키지 페이지로 이동합니다.
- 리스팅에서 가져오기 패키지를 찾습니다.
- 패키지() 메뉴에서 로그 다운로드(Download Logs)를 선택합니다.
가져온 데이터 보기
증분 수집: 증분 수집을 사용하면 지난 30일 이내에 가져온 모든 제3자 데이터 패키지와 함께 가장 최근에 가져온 제3자 데이터 패키지(기간에 관계없이)가 UI에 표시됩니다.
업로드 시 Workbench는 가져오기 패키지의 각 고유 파일에 대한 폼을 생성합니다. Workbench는 폼을 Veeva EDC에서 가져오거나 제3자 시스템에서 가져오는지에 관계없이 스터디의 각 고유 폼에 대한 코어 리스팅을 자동으로 생성합니다.
해당 코어 리스팅의 기본 CQL 쿼리는 다음과 같습니다.
SELECT @HDR, * from source.filename 위에 나온 실험실 가져오기 예시에서 CDB는 다음 쿼리를 사용하여 화학 및 혈액학(각 CSV 파일당 하나씩)이라는 두 개의 코어 리스팅을 생성합니다.
| 화학 |
|
| 혈액학 |
|
정의
CDB는 각 CSV 파일에 대한 폼 정의를 생성하여 가져온 데이터를 CDB Workbench 애플리케이션 내에서 "폼"으로 정의합니다. 해당 레코드는 CSV 파일 이름(확장자 없음)을 이름으로 사용합니다(예: "hematology"). 또한 CDB는 아이템 그룹 정의를 생성하여 폼 내에서 데이터 아이템을 함께 그룹화합니다. CDB는 CSV 파일 이름(확장자 없음) 앞에 "ig_"를 추가하여 이름을 지정합니다(예: "ig_hematology").
이 두 가지 정의는 모두 리스팅 내의 열(form_name 및 ig_name)로 표시됩니다. 리스팅의 CQL 쿼리를 편집하여 해당 열을 숨길 수 있습니다.