导入第三方数据
CDB 允许从第三方系统导入数据,以便在 CDB Workbench 应用程序中进行清理和报告。这旨在用于导入存在于 Veeva EDC 中受试者病例手册之外的受试者数据,例如,从 IRT 系统导入有关受试者的数据。
可用性:临床数据库(CDB)仅对 CDB 许可证持有者提供。请联系 Veeva 服务代表了解详细信息。
先决条件
在将数据导入 CDB 之前,组织必须执行以下任务:
- 创建研究、研究国家/地区和研究中心。
- 在 Veeva EDC Studio 中创建并发布病例手册定义、完整的设计定义记录和研究计划。详细信息请参见此处
- 为每名受试者创建病例手册记录
默认情况下,具有 CDMS 首席数据管理员(CDMS Lead Data Manager)标准研究角色的用户可以执行下述操作。如果贵组织使用自定义角色,则你的角色必须授予以下权限:
| 类型 | 权限标签 | 控制 |
|---|---|---|
| “标准”选项卡 | 工作台选项卡 | 能够通过工作台(Workbench)选项卡访问和使用 Data Workbench 应用程序 |
| 功能权限 | 查看导入 | 能够访问“导入(Import)”页面 |
| 功能权限 | API 访问权限 | 能够访问和使用 Vault EDC API。(使用 CDB 也需要此权限。) |
| 功能权限 | 批准导入 | 能够批准或拒绝包含配置更改的导入包 |
| 功能权限 | 下载导入包 | 能够下载导入包 |
| 功能权限 | 上传 3PD 数据包 | 支持通过 CDB 数据包加载程序导入数据。 |
准备要导入的数据
你可通过以下两种方式导入数据:以一系列 CSV 文件的形式上传至 Vault 的 FTP 服务器,通过 CDB 用户界面内的 CDB 数据包加载程序上传数据。
要导入数据,首先需要创建列出临床数据的 CSV 文件,以及描述这些数据和 CDB 应该如何处理这些数据的清单文件(.json)。然后,创建一个包含所有这些文件的 ZIP 包(.zip),以便导入到 CDB 中。
清单生成器:为便于创建文件,CDB 提供了 CDB 清单生成器。CDB 清单生成器是一个逐步向导,可指导在用户友好的界面中完成所有清单文件配置选项。在 CDB 清单生成器中,CDB 展示了每个导入选项,无需了解 JSON 即可进行设置。
数据 CSV 文件
为研究中的每个独立于 EDC 的数据收集表单创建一个 CSV 文件。对于每个 CSV 文件,必须提供四(4)个必需列,然后为每个执行数据条目提供一列。对于这四个必需列,可以任意命名,只要在每个 CSV 的清单文件中定义这些名称即可。请注意,这些列名称区分大小写,必须与清单文件中提供的值完全匹配。
除了“研究、研究中心、受试者、事件和序列”列之外,CDB 将每一列都视为一个数据条目,并会按此方式导入。每个列表对条目列的数量限制为 410 列。
| 列 | 描述 | 清单文件键位 |
|---|---|---|
| 研究 |
在此列中,提供研究的名称。为研究提供研究名称( 请勿使用“研究名称”作为此列的标题,因为这可能会导致导出包生成期间出现错误。
|
study |
| 研究中心 |
在此列中,提供研究中心的名称(研究中心编号)(来自 Veeva EDC 中的研究中心记录)。 请勿使用“研究中心名称”作为此列的标题,因为这可能会导致导出包生成期间出现错误。
如果未在清单文件中定义研究中心列并从 CSV 文件中排除该列,则 Workbench 可以根据受试者列进行匹配。执行此操作时,Workbench 期望受试者 ID 在研究级别是唯一的。 |
site |
| 受试者 |
在此列中,提供受试者的受试者 ID(来自 Veeva EDC 中受试者记录的姓名(Name)字段)。 请勿使用“受试者姓名”作为此列的标题,因为这可能会导致导出包生成期间出现错误。
|
subject |
| 事件 | 在此列中,提供与数据行关联的事件(访视)。根据清单文件中的 edc_matching 配置,可以使用 EDC 事件定义的名称或外部 ID、EDC 事件的事件日期,或者使用此列中的事件使 Workbench 创建独立于 EDC 计划的事件。还可以在清单文件中为所有行设置默认事件,并完全排除此列,这会将所有行分配给该事件。有关事件匹配的更多信息,请参见下文。 | event |
| 表单 *可选 |
在此列中,提供与数据行关联的表单(来自 Veeva EDC 中表单定义记录的名称)。仅当在单个 CSV 中导入多个表单的数据时,才需要此列。如果不包含此列,Workbench 会假设每个数据行都是单个表单。 有关表单匹配的更多信息,请参见下文。 |
form |
| 表单序列 *对于重复表单是必需的,对于非重复表单是可选的 |
如果表单重复,则为表单的序列号。重复表单表示在单个事件期间针对同一受试者多次收集相同的数据。然后,序列号会唯一标识数据行。如果某名受试者和事件有多个行(表单),Workbench 会假设该表单重复,并使用此列来设置序列号。如果表单重复,则此列为必填项,但如果表单不重复,则此列为可选项。在这种情况下,Workbench 默认将每行的序列号设置为“1”。 如果没有在重复表单中包含此列,可能会导致笛卡尔积,因为 Workbench 默认将序列号设置为“1”,导致各行具有相同的受试者/研究中心/表单/表单序列号标识符。 在 20R1 版本中,“sequence”被重命名为“formsequence”。在 20R2 版本(2020 年 8 月)发布之前,可以继续使用“sequence”导入数据。 |
formsequence |
| 条目组 *可选 |
在此列中,提供与之后的条目列关联的条目组(来自 Veeva EDC 中条目组定义记录的名称)。仅在为多个条目组的表单导入数据时,才需要此列。如果不包括此列,Workbench 会假设数据行中的所有条目都在同一个条目组中。 有关条目组匹配的更多信息,请参见下文 |
itemgroup |
| 条目组序列 *对于重复条目组是必需的,如果非重复条目组是可选的 |
如果条目组是重复的,则为条目组的序列号。重复条目组表示在单个表单中针对同一受试者多次收集相同的数据。然后,序列号会唯一标识数据行。如果某名受试者和事件的表单行有多组条目,Workbench 会假设该表单重复,并使用此列来设置序列号。 如果没有在重复条目组中包含此列,可能会导致笛卡尔积,因为 Workbench 默认将序列号设置为“1”,导致各行具有相同的受试者/研究中心/表单/表单序列/条目组/条目组序列号标识符。 对于非重复条目组,此列是可选的,因此,如果没有重复的条目组,则可以留空或不提供。在这种情况下,Workbench 默认将每行的序列号设置为“1”。 |
itemgroupsequence |
| 行 ID *可选 21R2 和之前的版本 |
提供列的列表,当这些列的值组合在一起时,Workbench 可以用来唯一标识行。这在没有用于标识序列的数字键位时非常有用。例如,在导入实验室数据时,可以使用研究、受试者和实验室检测来唯一标识行。如果包含 rowid 列映射,Workbench 会忽略序列的所有值,并自动将序列设置为“1”。如果省略,Workbench 将使用默认列数组来标识行:study、subject、event、form 和 formsequence。虽然仍支持为 rowid 提供单个列列表,但计划在未来版本中删除。相反,将 groupid 和 distinctid 定义为 rowid 的列列表。参见以下行。 |
rowid |
| 行 ID *可选 21R3 和之后的版本 |
组 ID(Group ID):该字段为 21R3 版本发布前创建的数据导入遗留字段。21R3 版本及之后的数据导入应使用“唯一 ID(Distinct ID)”。使用组 ID 会导致数据完整性问题,因为它不会像唯一 ID 那样自动递增表单或条目组序列号。例如,若数据未明确映射表单或条目组序列号,系统会默认设为 1,可能导致多条记录导入时的研究(Study)、研究中心(Site)、受试者(Subject)、事件(Event)、表单(Form)、表单序列号(Form Sequence Number)、条目组(Item Group)及条目组序列号(Item Group Sequence Number)值完全相同。因此,CQL 会将这些记录判定为重复项,进而导致列表结果不一致。 唯一 ID:提供一个列列表,当这些列的值组合在一起时,Workbench 可以用来将在组的上下文中唯一标识记录(由 行外部 ID:可以为数据行分配一个外部 ID,类似于来自 EDC 的外部 ID。这有助于识别第三方数据质疑的来源。为 |
rowid 与 groupId,distinctid,和 rowexternalid |
连字符类型:连字符有两种不同类型,分别是“连字符减号”和“Unicode 连字符”。连字符减号是你按键盘上的 -(连字符)键通常输入的字符。在大多数现代字体中,这两种字符在视觉上是相同的。Veeva CDB 仅支持在数据导入时使用连字符减号。如果你导入的内容中包含 Unicode 连字符,导入将会失败。
以下是 CSV 文件示例:
| STUDY_ID | SITE | SUBJECT_ID | VISIT | INITIALS | DOB | GENDER | RACE |
|---|---|---|---|---|---|---|---|
| S.Deetoza | 101 | 101-1001 | Screening | CDA | 03-27-1991 | F | Hispanic |
在此示例中,有以下列映射:
- 研究:STUDY_ID
- 研究中心:SITE
- 受试者:SUBJECT_ID
- 事件:VISIT
INITIALS、DOB、GENDER 和 RACE 列都是数据条目。
清单文件
清单文件为 CDB 提供研究和源,列出 ZIP 中的文件,并为每个文件列出映射到所需数据点的列。
源是一个自定义值,允许标识数据包的内容。此值存储在 Workbench 的源(Source)字段中,因此可以通过 CQL 在 Workbench 中标识此数据包中的数据。源(Source)值在研究中必须是唯一的。
为研究提供研究名称(study__v)记录。为研究提供研究名称(study__v)记录。如果研究名称包含空格字符,则必须在清单文件中使用带有空格的值,但在数据文件中必须将空格替换为下划线(_)。
为源指定数据源。系统将此源应用于所有导入数据。然后,作为数组,列出每个 CSV 文件,包括其文件名(带扩展名)及其列映射,作为“数据”的值。
可以选择在导入文件中包含有关每个数据条目的配置元数据。请参见下面的详细信息。
将文件另存为“manifest.json”。
请注意,Workbench 仅接受具有此确切文件名(区分大小写)和扩展名的清单文件。
示例清单:单表单
以下是 Deetoza 研究的示例清单文件,该文件从包含调查表单的 eCOA 导入一个数据包:
{ "study": "Deetoza", "source": "eCOA", "data": [ { "filename": "Survey.csv", "study": "protocol_id", "site": "site_id", "subject": "patient", "event": "visit_name" } ] } 示例清单:多表单
以下是 Deetoza 研究的示例清单文件,该文件从实验室供应商处导入一个数据包,其中包含生化和血液学检查表单:
{ "study": "Deetoza", "source": "lab", "data": [ { "filename": "Chemistry.csv", "study": "STUDY_ID", "site": "SITE_ID", "subject": "SUBJECT_ID", "event": "VISIT", "formsequence": "LAB_SEQ" }, { "filename": "Hematology.csv", "study": "STUDY_ID", "site": "SITE_ID", "subject": "SUBJECT_ID", "event": "VISIT", "formsequence": "LAB_SEQ" } ] } 还可以使用行 ID 映射,并使用单个 CSV 文件导入生化和血液学检查实验室数据。在该 CSV 文件中,可以使用"实验室检测集"列来指示该行的生化或血液学检查结果。
{ "study": "Deetoza", "source": "lab", "data": [ { "filename": "Labs.csv", "study": "STUDY_ID", "site": "SITE_ID", "subject": "SUBJECT_ID", "event": "VISIT" } ] } 表单标签覆盖
在导入第三方数据源时,可以通过映射 form_label 键为表单 定义标签,以便在列表中通过 CQL 进行引用。
可以通过两种不同的方式使用 form_label 键,根据清单中是否使用了 form 键,两种方式的预期输入会有所不同。
如果清单中使用了 form 键来映射数据文件中的某一列,并且同时也使用了 form_label 键,则 form_label 键的输入内容也将表示数据文件中可以找到表单标签的列。form_label 键将与 form 键一起成为数据数组的一部分:
{ "study": "Deetoza", "source": "lab", "data": [ { "filename": "hematology_lpanel.csv", "study": "STUDY_ID", "site": "SITE_ID", "subject": "SUBJECT_ID", "event": "VISIT", "formsequence": "LAB_SEQ", "form": "FORM_NAME_COLUMN" "form_label": "FORM_LABEL_COLUMN" } ] } 如果清单中未使用 form 键,而使用了 form_label 键,则 form_label 键的预期输入是一个字符串,该字符串值等于要使用的表单标签。要为表单 定义标签,请将标签 form_label 添加到数据数组:
{ "study": "Deetoza", "source": "lab", "data": [ { "filename": "hematology_lpanel.csv", "study": "STUDY_ID", "site": "SITE_ID", "subject": "SUBJECT_ID", "event": "VISIT", "formsequence": "LAB_SEQ", "form_label": "Hematology" } ] } 要覆盖条目 的名称 和标签,请将名称和标签属性添加到条目的配置。请参见下面的详细信息。
可选:事件匹配
默认情况下,Workbench 将表单的 CSV 文件中的事件与 Veeva EDC 中匹配的事件定义记录的名称进行匹配。还可以选择让 Workbench 根据事件定义的外部 ID 进行事件匹配。还可以在清单文件中定义一个默认事件,并将所有行自动分配给该事件。如果数据是在 EDC 计划事件之外收集的,则可以选择不映射到任何 EDC 事件,并让 Workbench 根据需要创建事件以匹配导入包中的事件。
如果事件位于重复事件组内,Workbench 会使用事件定义的外部 ID,并在其后附加序列号以进行匹配。文件中每个唯一事件的序列号会递增。如果一个事件在多个事件组中重复使用,则不会被视为重复。在这种情况下,Workbench 会将其匹配到 EDC 计划中的第一个匹配事件。
默认行为
如果在清单文件中未包含任何事件匹配配置,则适用以下默认值:
- Workbench 使用事件定义的名称进行匹配。
- Workbench 尝试与现有 EDC 事件匹配。如果 EDC 中没有匹配的事件,Workbench 会创建一个新事件。
这种默认行为相当于以下清单配置:
{ "study": "Deetoza", "source": "Labs", "edc_matching": { "event": { "target": ["name"], "generate": true } } } 按名称匹配(默认)
如果在清单文件中未包含 edc_matching,Workbench 将自动使用事件定义的名称进行匹配。还可以在清单文件中指定基于名称的批处理。
{ "study": "Deetoza", "source": "Labs", "edc_matching": { "event": { "target": ["name"] } } } 按外部 ID 匹配
要根据事件定义的外部 ID(以前称为 OID)进行匹配,必须包含 edc_matching,并将事件目标设置为 external_id。请参见以下示例摘录:
{ "study": "Deetoza", "source": "Labs", "edc_matching": { "event": { "target": ["external_id"] } } } 设置默认事件
可以选择将事件设为清单文件中的默认事件,而不在 CSV 中列出事件。然后,Workbench 会自动将该 CSV 文件中的所有行分配给该事件。这由 default 键位控制。使用事件定义的名称作为 default.可以为特定数据文件设置默认值,或在数据包级别设置默认值。
示例:数据包级别默认事件
{ "study": "Deetoza", "source": "lab", "edc_matching": { "event": { "default": "treatment_visit" } }, "data": [ { "filename": "Labs.csv", "study": "STUDY_ID", "site": "SITE_ID", "subject": "SUBJECT_ID", "event": "VISIT", "rowid": ["LAB_TEST_SET", "LAB_TEST_SEQ"] } ] } 示例:文件包级别默认事件
{ "study": "Deetoza", "source": "Labs", "edc_matching": { "event": { "default": "treatment_visit", } } } 处理未匹配事件
默认情况下,如果 Workbench 无法按名称或外部 ID 将事件与 EDC 中的事件匹配,Workbench 会为特定于源的任何非 EDC 事件创建新事件。这些新事件将成为整个 Workbench 标题事件记录的一部分。(可通过 @HDR.Event 访问)。这由 generate 键位控制。默认行为的清单配置为 generate: true。如果数据是在 EDC 事件计划之外收集的,可以通过将 generate 设置为 false 来选择不与任何 EDC 事件匹配。如果将 generate 设置为 false,Workbench 将不会创建新的事件定义。相反,对于没有匹配 EDC 事件的任何行,导入都将失败。
示例:按外部 ID 匹配并忽略未匹配事件
{ "study": "Deetoza", "source": "Labs", "edc_matching": { "event": { "target": ["external_id"], "generate": false } } } 如果数据完全在 EDC 计划之外收集,可以选择让 Workbench 为每个事件创建新事件,而无需尝试与 EDC 事件匹配。为此,请将 event 设置为 false,如以下示例所示:
{ "study": "Deetoza", "source": "Labs", "edc_matching": { "event": false } } 可选:表单和条目组映射
可以选择将 CSV 文件中的行映射到不同的表单和条目组,包括定义 Workbench 如何解释数据集中的重复表单和条目组。这使得 Workbench 能够将单个 CSV 转换为多个表单和条目组,而不是单个表单和单个条目组。
例如,实验室表单可以包含多个条目组 - 每个实验室检测类别一个条目组。可以使用 itemgroup 列来指示行中的数据条目所属条目组。Workbench 将行中所有未映射的列视为条目。Workbench 将这些条目导入到行指定的条目组内。可以在条目配置中为这些列指定额外的元数据。请参见下面的详细信息。
使用下表了解 Workbench 将如何通过不同表单和条目组配置场景来处理数据:
| 定义表单 | 定义条目组 | 结果 |
|---|---|---|
| 否(No) | 否(No) | Workbench 将每行视为单个表单。 |
| 是(Yes) | 否(No) | Workbench 将每行视为不同表单,从表单列中标识表单。表单列中的每个唯一值都作为不同的表单处理。 |
| 否(No) | 是(Yes) | Workbench 将每行视为一个条目组(如 itemgroup 列中所定义),并将这些行按受试者和表单分组在一起。要将每个条目组视为重复的条目组,请使用 itemgroupsequence 列。 |
| 是(Yes) | 是(Yes) | Workbench 按受试者、表单和条目组将行分组在一起。表单列中的每个唯一值都作为不同的表单处理,而条目组列中的每个唯一值作为一个条目组。 |
示例清单:多表单
在以下示例中,“Labs.csv”文件包含多个表单。这些表单在“Labs.csv”文件的表单列中被标识。
{ "study": "Deetoza", "source": "lab", "data": [ { "filename": "Labs.csv", "study": "protocol_id", "site": "site_id", "subject": "subject_id", "event": "visit", "form": "form" } ] } 
示例清单:多个条目组
在以下示例清单文件中,实验室表单具有多个条目组。这些表单在“Labs.csv”文件的lab_category列中被标识。
{ "study": "Deetoza", "source": "lab", "data": [ { "filename": "Labs.csv", "study": "protocol_id", "site": "site_id", "subject": "subject_id", "event": "visit", "item_group": "lab_category" } ] } 
可选:代码列表配置
你可以配置代码列表 (Codelists) 以引用代码列表类型的条目 (Items)。代码列表是一组代码和解码对,用户可以在输入数据时从中进行选择。
对于每个代码列表,你可以提供姓名、external_id(可选)和 codelist_data。codelist_data 可接受代码和解码对。
"codelists": [ { "name": "SEX", "external_id": "SEX", "codelist_data": [ { "code": "M", "decode": "Male" }, { "code": "F", "decode": "Female" } ] } ] 可选:条目配置
在清单文件中,可以包含条目元数据,以告知 CDB Workbench 如何处理数据条目。可以为每个条目指定数据类型,并根据数据类型选择指定其他属性。
当省略条目配置时,CDB Workbench 会将所有条目视为文本。
简单配置与高级配置
条目“config”对象有两种配置格式,简单和高级。对于简单配置,只需指定条目的数据类型。条目的属性使用默认值。对于高级配置,需指定数据类型和属性。
"items" { "Weight": "float" }"items" { "Weight": { "type": "float", "precision": 2 } }定义名称和标签
可以在条目 的配置中定义其名称 和标签。这些键可用于与所有条目数据类型进行映射。
映射 label 键以提供标签。如果省略,则此值默认为匹配条目的名称。默认情况下,Workbench 将列标题用作条目 的名称。可以通过在清单文件中映射 name_override 键来覆盖此名称。名称 只能包含字母数字字符、短划线和下划线。不允许包含空格。
"items": { "REQ_NUM": { "type": "text", "length": 10, "name_override": "REQUESTION_NUM", "label": "Requisition Number" }, "EVENTTYP": { "type": "text", "length": 10, "label": "Event Type" }, "COL_DATE": { "type": "date", "format": "ddMMMyyyy", "name_override": "COLLECTION_DATE", "label": "Collection Date" }, "COL_TIME": { "type": "time", "format": "HH:mm", "label": "Collection Time" } } 按数据类型划分的可用属性
每种数据类型有不同的配置属性可用。
| 数据类型 | 示例配置 | 属性 | 属性描述 |
|---|---|---|---|
| 文本 |
|
长度 | 允许的字符数。默认长度是 1500。 |
| 整数 |
|
Min | 最小(最低)允许值。默认值是 -2,147,483,647。 |
| Max | 最大(最高)允许值。默认值是 2,147,483,647。 | ||
| 浮点值(带小数的数字) |
|
长度 |
小数点左侧和右侧允许的最大位数。 如果最大值的位数超过该属性的位数,Workbench 将使用最大值的位数。 |
| 精确度 |
允许的小数位数。默认值是 5。 如果最大值的小数位数超过该属性的小数位数,Workbench 将使用最大值的小数位数。 |
||
| Min | 最小(最低)允许值。默认值是 -4,294,967,295。 | ||
| Max | 最大(最高)允许值。默认值是 4,294,967,295。 | ||
| 日期 |
|
格式 |
用于解析日期值的格式模式。请参阅以下支持日期格式列表。 默认值是“yyyy-MM-dd”。 |
| 日期时间 |
|
格式 |
用于解析日期时间值的格式模式。请参阅以下支持日期时间格式列表。 默认值是“yyyy-MM-dd HH:mm”。 |
| 时间 |
|
格式 |
用于解析时间值的格式模式。请参阅以下支持时间格式列表。 默认值是“HH:mm”。 |
| 布尔值 |
|
不适用 | 布尔值数据类型没有任何配置属性。 Workbench 接受布尔值“true”/“false”、“yes”/“no”和“1”/“0”。 |
| 编码列表 |
|
编码列表 | 其指定了此条目使用的代码列表。代码列表是一组规定的代码和解码对(代码列表条目),用户可以在输入数据时从中进行选择。参见上文如何定义代码列表。 |
支持的日期和时间格式模式
下面列出的格式模式可用于日期、日期时间和时间条目。日期时间条目合并日期和时间模式,例如“yy-MM-dd HH:mm””。如果对日期使用时间格式模式(反之亦然),导入将失败并显示错误(D-012)。
| 格式模式 | 示例 | 描述 |
|---|---|---|
| dd MM yy | 02 18 20 | 2 位数字的日期、2 位数字的月份和 2 位数字的年份,使用空格( )分隔符 |
| dd MM yyyy | 02 18 2020 | 2 位数字的日期、2 位数字的月份和完整年份,使用空格( )分隔符 |
| dd MMM yyyy | 02 Feb 2020 | 2 位数字的日期、缩写的月份(文本)和完整年份,使用空格( )分隔符 |
| dd-MM-yy | 18-02-20 | 2 位数字的日期、2 位数字的月份和 2 位数字的年份,使用破折号(-)分隔符 |
| dd-MM-yyyy | 18-02-2020 | 2 位数字的日期、2 位数字的月份和完整年份,使用破折号(-)分隔符 |
| dd-MMM-yyyy | 18-Feb-2020 | 2 位数字的日期、缩写的月份(文本)和完整年份,使用破折号(-)分隔符 |
| dd-MMM-yyyy HH:mm:ss | 18-Feb-2020 12:10:50 | 2 位数字的日期、缩写的月份(文本)和完整的年份,使用破折号(-)分隔符,时间包括秒 |
| dd/MMM/yy | 18/Feb/20 | 2 位数字的日期、缩写的月份(文本)和 2 位数字的年份,使用正斜杠(/)分隔符 |
| dd-MMM-yy | 18-Feb-20 | 2 位数字的日期、缩写的月份(文本)和 2 位数字的年份,使用破折号(-)分隔符 |
| ddMMMyy | 18Feb20 | 2 位数字的日期、缩写的月份(文本)和 2 位数字的年份(无分隔符) |
| dd MMM yy | 18 Feb 20 | 2 位数字的日期、缩写的月份(文本)和 2 位数字的年份,使用空格( )分隔符。 |
| dd.MM.yy | 18.02.20 | 2 位数字的日期、2 位数字的月份和 2 位数字的年份,使用句点(.)分隔符 |
| dd.MM.yyyy | 18.02.2020 | 2 位数字的日期、2 位数字的月份和完整年份,使用句点(.)分隔符 |
| dd/MM/yy | 18/02/20 | 2 位数字的日期、2 位数字的月份和 2 位数字的年份,使用正斜杠(/)分隔符 |
| dd/MM/yyyy | 18/02/2020 | 2 位数字的日期、2 位数字的月份和完整年份,使用正斜杠(/)分隔符 |
| ddMMMyyyy | 18Feb2020 | 2 位数字的日期、缩写的月份(文本)和完整年份(无分隔符) |
| ddMMyy | 180220 | 2 位数字的日期、2 位数字的月份和 2 位数字的年份(无分隔符) |
| ddMMyyyy | 18022020 | 2 位数字的日期、2 位数字的月份和完整年份(无分隔符) |
| MM/dd/yy | 02/18/20 | 2 位数字的月份、2 位数字的日期和 2 位数字的年份,使用正斜杠(/)分隔符 |
| MM/dd/yyyy | 02/18/2020 | 2 位数字的月份、2 位数字的日期和完整年份,使用正斜杠(/)分隔符 |
| MMddyy | 021820 | 2 位数字的月份、2 位数字的日期和 2 位数字的年份(无分隔符) |
| MMddyyyy | 02182020 | 2 位数字的月份、2 位数字的日期和完整年份(无分隔符) |
| MMM dd yyyy | Feb 18 2020 | 缩写的月份(文本)、2 位数字的日期和完整年份,使用空格( )分隔符 |
| MMM/dd/yyyy | Feb/18/2020 | 完整月份(文本)、2 位数字的日期和 4 位数字的年份,使用正斜杠(/)分隔符 |
| MMMddyyyy | Feb182020 | 完整月份(文本)、2 位数字的日期和 4 位数字的年份(无分隔符) |
| yy-MM-dd | 20-02-18 | 2 位数字的年份、2 位数字的月份和 2 位数字的日期,使用破折号(-)分隔符 |
| yy/MM/dd | 20/02/18 | 2 位数字的年份、2 位数字的月份和 2 位数字的日期,使用正斜杠(/)分隔符 |
| yyyy MM dd | 2020 02 18 | 完整年份、2 位数字的月份和 2 位数字的日期,使用空格( )分隔符 |
| yyyy-MM-dd | 2020-02-18 | 完整年份、2 位数字的月份和 2 位数字的日期,使用破折号(-)分隔符 |
| yyyy-MM-dd'T'HH:mm | 2020-02-18T12:10 | 完整年份、2 位数字的月份和 2 位数字的日期,使用破折号(-)分隔符,包含时间 |
| yyyy.dd.MM | 2020.18.02 | 完整年份、2 位数字的日期和 2 位数字的月份,使用句点(.)分隔符 |
| yyyy.MM.dd | 2020.02.18 | 完整年份、2 位数字的月份和 2 位数字的日期,使用句点(.)分隔符 |
| yyyy/MM/dd | 2020/02/18 | 完整年份、2 位数字的月份和 2 位数字的日期,使用正斜杠(/)分隔符 |
| yyyyMMdd | 20200218 | 完整年份、2 位数字的月份、2 位数字的日期(无分隔符) |
| yyyyMMdd'T'HH:mm | 2020218T12:10 | 完整年份、2 位数字的月份、2 位数字的日期(无分隔符),包含时间 |
| dd/MM/yyyy HH:mm | 18/02/2020 18:30 | 2 位数字的日期、2 位数字的月份、4 位数字的年份,使用斜线(/)分隔符,包含 24 小时制时间 |
| MM/dd/yyyy HH:mm | 02/18/2020 18:30 | 2 位数字的月份、2 位数字的日期、4 位数字的年份,使用斜线(/)分隔符,包含 24 小时制时间 |
| yyyy-MM-dd'T'HH:mm:ss+HH:mm | 2020-02-18T18:30:22+00:00 | 4 位数字的年份、2 位数字的月份、2 位数字的日期,使用破折号(-)分隔符,包含 24 小时制时间(含秒),UTC 时间的偏移量(+HH:mm) 注意:清单文件应使用单引号(')将 T 括起来,但 CSV 文件中不能包含这些单引号。 |
| yyyy-MM-dd'T'HH:mm:ssZ | 2020-02-18T18:30:22Z | 4 位数字的年份、2 位数字的月份、2 位数字的日期,使用破折号(-)分隔符,包含 24 小时制时间(含秒),UTC 时间 注意:清单文件应使用单引号(')将 T 括起来,但 CSV 文件中不能包含这些单引号。 |
| yyyyMMdd'T'HH:mm:ssZ | 20200218T18:30:22Z | 4 位数字的年份、2 位数字的月份、2 位数字的日期和 24 小时制时间(含秒),UTC 时间 注意:清单文件应使用单引号(')将 T 括起来,但 CSV 文件中不能包含这些单引号。 |
| yyy-MM-dd'T'HH:mm:ss | 2020-2-18T12:10:41 | 完整年份、2 位数字的月份和 2 位数字的日期,使用破折号(-)分隔符,包含时间(含秒) 注意:清单文件应使用单引号(')将 T 括起来,但 CSV 文件中不能包含这些单引号。 |
| ddMMyyyy'T'HH:mm:ss | 10122024T16:15:30 | 2 位数字的日期、2 位数字的月份、4 位数字的年份,无分隔符,包含 24 小时制时间 注意:清单文件应使用单引号(')将 T 括起来,但 CSV 文件中不能包含这些单引号。 |
| yyyyMMdd HH:mm:ss | 20241210 16:15:30 | 4 位数字的年份、2 位数字的月份、2 位数字的日期(无分隔符),包含 24 小时制时间(含秒) |
| MM/dd/yyyy HH:mm:ss | 12/10/2024 16:15:30 | 2 位数字的月份、2 位数字的日期、4 位数字的年份,使用斜线(/)分隔符,包含 24 小时制时间(含秒) |
| yyyy-MM-dd'T'HH:mm:ss | 2024-12-10T16:15:30 | 4 位数字的年份、2 位数字的月份、2 位数字的日期,使用破折号(-)分隔符,包含 24 小时制时间 注意:清单文件应使用单引号(')将 T 括起来,但 CSV 文件中不能包含这些单引号。 |
| HH:mm | 18:30 | 24 小时制时间 |
| HH:mm:ss | 18:30:15 | 24 小时制时间,含秒 |
示例数据包:单个表单、条目元数据
以下是来自 Verteo Pharma 随机化供应商的示例导入包,其中包含带有条目元数据的随机化表单:
manifest.json:
{ "study": "Cholecap", "source": "IRT", "data": [{ "filename": "Randomization.csv", "study": "protocol_id", "site": "site_id", "subject": "patient", "event": "visit_name", "items": { "randomization_number": { "type": "integer", "length": "14" }, "date_of_randomization": { "type": "date", "format": "yyyy-MM-dd" } } }] } Randomization.csv:
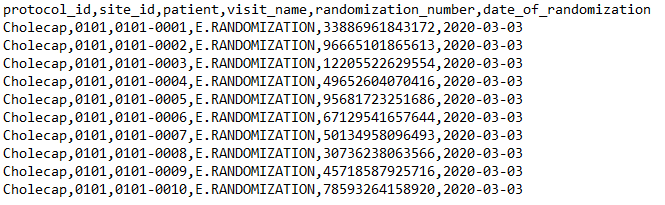
严格导入
清单文件中的严格导入参数允许将数据摄取限制为仅清单中定义的条目,而不是数据 CSV 文件中的所有条目列。可以将此选项应用于整个数据包或单个文件。文件级设置会覆盖数据包级设置。
“strict_import” 参数可以设置为真(true)或假(false)。将此项设置为真(true)即启用严格导入。
可选:限制数据(盲态)
可以在条目、行、列表数据文件和源级别限制(设盲)数据,以隐藏无权访问受限数据的用户数据。例如,研究可能只为使用研究药物的受试者订购某些实验室检测。知道受试者已进行的实验室检测将揭示其身份。可以限制此信息,以防止盲态用户识别这些受试者。
| 限制级别 | 清单文件配置 |
|---|---|
| 条目 |
|
| 表单记录 *限制要导入的特定表单记录中的数据。使用描述该行是否为盲态的列。 |
|
| 列表数据文件 |
|
| 源数据包 |
|
对于有权访问受限数据的用户(通常是首席数据管理员),受限数据的行为方式与不受限数据相同。对于盲态用户(没有受限数据访问权限的用户),以下行为规则适用于任何导入的受限数据:
- 如果条目(列)受限:
- CQL 投影不会返回受限条目的列。
- CQL 投影不会返回引用受限条目的任何衍生列。
- 如果盲态用户在 CQL 语句中引用了受限条目,CQL 仍然不会返回该列。
SHOW和DESCRIBE不会返回受限条目。
- 如果行受限:
- 结果集不会返回来自表单或条目组的任何行。
- 如果列表文件(csv)受限:
- 列表中默认包含
@HDR列,但不包含任何条目列。
- 列表中默认包含
- 如果源(数据包)受限:
- CQL 不会在任何列表中返回来自受限源的任何条目或列结果。
- CDB 将源中的所有条目定义、条目组定义和表单定义标记为受限。
- 将所有数据行都标记为受限。
- 默认的 @HDR 列仍将显示在核心列表中。
ZIP 包
创建清单文件和 CSV 文件之后,将这些文件压缩为 ZIP 文件。不要在压缩之前将这些文件放入文件夹中。可以随意命名这个 ZIP 文件夹。但建议使用唯一标识符对其进行命名,例如“研究名称_源_日期时间.zip”。不得在 ZIP 文件夹中包含任何文件夹。所有 CSV 文件和清单文件必须位于同一级别。
访问 Vault 的 FTP 服务器
域中的每个 Vault 有其自己的 FTP 暂存服务器。FTP 服务器是上传到 Vault 或从 Vault 提取的文件的临时存储区域。
服务器 URL
每个暂存服务器的 URL 与相应的 Vault 相同,例如,veepharm.veevavault.com。
如何访问 FTP 服务器
可以使用收藏的 FTP 客户端或通过命令行访问暂存服务器。
对 FTP 客户端使用以下设置:
- 方案:FTP(文件传输方案)
- 加密:需要显式 FTP over TLS(FTPS)。这是一项安全要求。网络基础设施必须支持 FTPS 流量。
- 端口:通常不需要添加,默认为端口 21。
- 主机:{DNS}.veevavault.com。例如:“veepharm”是 veepharm.veevavault.com 中的 DNS。
- 用户:{DNS}.veevavault.com+{用户名}。使用登录时的用户名。例如:veepharm.veevavault.com+tchung@veepharm.com。
- 密码:在此 Vault 中的登录密码。与标准登录使用的密码相同。
- 登录类型:正常
- 传输文件类型(Transfer File Type):以二进制形式传输文件
如果在上传大型文件时遇到问题,请将 FTP 客户端超时设置增加到 180 秒。
如果在代理或防火墙上启用了远程验证,来自你网络上的计算机到 Veeva FTP 服务器的 FTP 流量可能会被拒绝。如果可能,与 IT 部门合作以禁用远程验证。如果无法禁用,请联系 Veeva 支持人员。
FTP 目录结构
在用户目录中,有一个“workbench”目录。这是上传第三方数据的地方。CDB 会自动识别放置在此处的任何文件。
CDB 会将任何成功导入的文件移动到“workbench/_processed”中。请参见下面的详细信息。
导入数据
你可以通过两种方式将数据导入 Workbench:使用 FTP 服务器,或使用 CDB 用户界面内的 CDB 数据包加载程序。
通过 FTP 客户端导入
要使用 FTP 客户端导入数据,请使用选择的 FTP 客户端将 ZIP 文件上传到 FTP 暂存服务器的“Workbench”目录。将 ZIP 上传到 FTP 存储服务器之后,CDB 会导入 ZIP 并转换数据。
使用 CDB 数据包加载程序导入
要使用 Workbench 用户界面导入数据,请通过 CDB 数据包加载程序上传 ZIP 文件。
访问 CDB 数据包加载程序的操作步骤如下:
-
在顶部导航栏中单击 上传数据包(Upload Data Packages),或从导航抽屉中单击数据包加载程序(Package Loader)。
-
将 ZIP 文件拖放到拖放(Drag and drop)区域。也可以单击此区域浏览并上传文件。

- 已上传文件会显示在已选数据包(Selected Packages)下方。单击 X 可移除文件。
- 单击上传(Upload)。
单次最多可上传 10 个数据包,单个文件大小不得超过 200MB。若文件超出大小限制,系统会显示错误消息并阻止上传。
导入完成后,Workbench 会向你及任何其他订阅该源的用户发送电子邮件通知。如果重新处理包的结果与之前的加载有所变化,Workbench 也将向你和订阅该源的用户发送通知。
成功导入
在成功导入之后:
- CDB 创建所有定义记录以及它们之间的关系。
- CDB 自动将所有导入记录的源字段设置为在清单中提供的值,以唯一标识数据源。(从 Veeva EDC 导入的任何表单的该值默认设置为“EDC”。第三方数据源和 OpenEDC 主要来源禁止使用“EDC”作为来源名称。)
- CDB 为导入包中的每个唯一表单创建一个核心列表。请参见下面的详细信息。
- 若通过 FTP 客户端导入,CDB 会将 ZIP 文件从
- “workbench”目录转移至“workbench/_processed/{study}/{source}”。CDB 还会将导入的日期和时间附加到文件名中。
- 若通过数据包加载程序导入,文件将从“Vault 文件暂存区”转移至“workbench/_processed/{study}/{source}”目录。
现在可以在 Workbench 中查看你的列表。在当前版本中,Workbench 不会立即显示你的新列表。首先,导航到研究的列表(Listings)页面,单击打开另一个核心列表,然后返回列表页面。此时,你的新数据列表将显示在列表中。现在可以单击其中一个列表的名称(Name)打开它。
导入失败
导入失败时:
- CDB 会将尝试导入的日期和时间附加到 ZIP 文件的文件名中。
- 若通过 FTP 客户端导入,CDB 会将 ZIP 文件从
- “workbench”目录转移至“workbench/_error”
- 若通过 CDB 数据包加载程序导入,文件将从“Vault 文件暂存区”转移至“workbench/_error”目录
- CDB 会创建一个错误日志(“<导入日期时间>_<数据包名称>_错误.csv”)。
请参阅此可能的错误列表以及如何解决这些错误。
错误限制:导入日志最多只能捕获 10,000 个错误和警告,达到此阈值后将停止记录。
查看来源与导入数据包
通过导入页面可查看研究的全部来源及关联导入数据包。
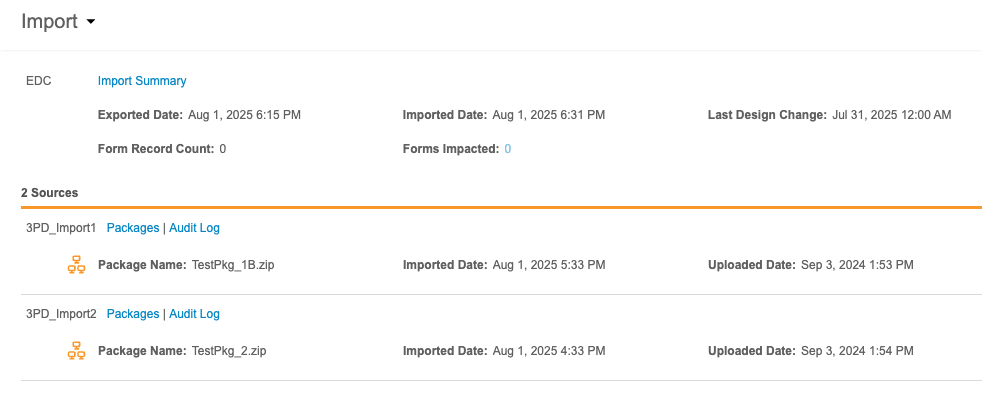
页面顶部显示主要来源(Veeva EDC 或第三方 EDC 系统的导入信息,包括:
- 导入摘要下载链接
- 导出日期(数据从 EDC 系统导出的日期)
- 导入日期(数据导入 Workbench 的日期)
- 上次设计更改(EDC 系统中研究设计/方案的最近更改日期和时间)
- 表单记录计数(受新导入数据包影响的表单记录数量)
- 受影响表单数(受新导入数据包影响的表单数量)
导入摘要汇总了 Veeva EDC 的所有增量加载数据。每日数据包含以下信息:
- 日期
- 增量数据包数量(当日导入的增量数据包个数)
- 完整数据包数量(当日导入的完整数据包个数)
- 错误(用“是”或“否”标识导入过程中是否出现错误)
可按导入日期范围(Import Date Rang)筛选此列表。
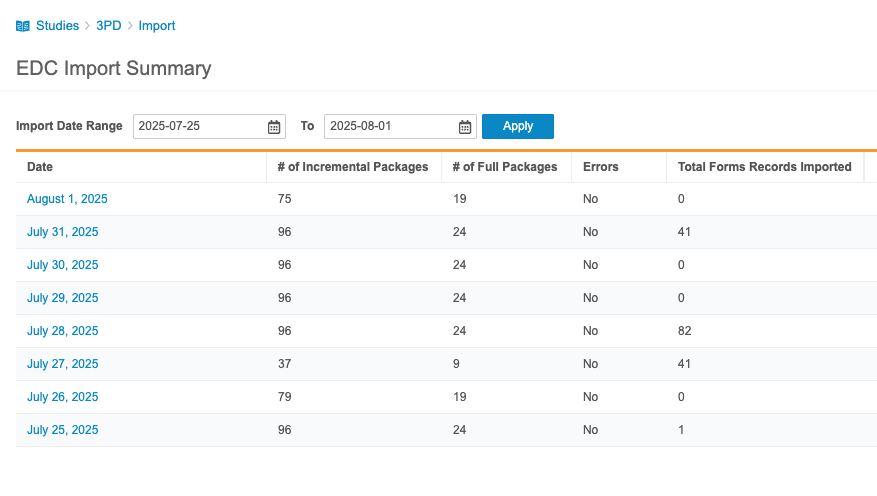
单击任意日期可查看当日所有数据包详情。对于每个导入数据包,Workbench 会显示以下信息:
- EDC 导出日期
- 上传日期
- 导入日期
- 完整加载(true/false 复选框)
- 导入的表单记录总数
- 状态
- 详细信息
审查和批准更改的导入
为了确保导入到 CDB 的数据不会改变已批准的格式和结构,CDB 会检测每个第三方源从一次加载到下一次加载的数据包配置中的任何更改。
如果系统检测到数据包、文件或盲态级别的配置更改,或者 CSV 文件结构发生更改,CDB 将暂停导入过程。数据包不会被处理,并进入已暂停(Paused)状态,直到具有批准权限的用户批准或拒绝数据包。如果用户批准了数据包,CDB 会记录批准原因并导入数据包。数据包获得批准后,CDB 会通过电子邮件通知订阅批准更改的用户。CDB 会在所有关联列表和视图上显示更改指示器。用户可以关闭此指示器,并下载任何列表或视图的表单更改日志。如果用户拒绝数据包,CDB 会记录拒绝原因,将数据包标记为被拒绝(Rejected),并将其分配为未导入(Not Imported)状态。CDB 然后会恢复到该源上最后成功导入的数据包。
当数据包处于已暂停状态时,相同源的所有其他已上传数据包将进入队列,等待暂停的数据包获得批准或被拒绝。暂停的数据包获得批准或被拒绝后,CDB 就会跳到最后一个排队的数据包进行处理。队列中最后一个已暂停的数据包和最后一个数据包之间的任何数据包将不会被处理。例如,如果“数据包 1”已上传并暂停,则上传数据包 2-5,而“数据包 1”仍处于暂停状态,在“数据包 1”获得批准或被拒绝后,CDB 将跳至“数据包 5”,而不处理数据包 2-4。
对于新源的第一个上传数据包,CDB 会自动应用已暂停状态,用户必须先批准或拒绝第一个数据包,然后系统中才会显示来自该源的任何数据。
对于需要批准的数据包,Workbench 现在有一个数据包详细信息(Package Detail)面板,其中包含差异(Differences)和关联对象(Associated Objects)选项卡。差异选项卡显示当前数据包和先前数据包之间清单的更改。用户可以查看他们批准的更改的先前和当前值。关联对象选项卡显示数据包中的更改可能影响的导出定义、列表和视图。
批准或拒绝导入数据包需要拥有批准导入权限,默认情况下,该权限分配给标准 CDMS 超级用户(CDMS Super User)和 CDMS 首席数据管理员(CDMS Lead Data Manager)研究角色。
批准导入
要批准导入,请执行以下操作:
- 导航至你的来源。
- 按待批准项筛选导入数据列表。
-
从数据包菜单()中,选择查看数据包详细信息(View Package Details)。
- 在数据包详细信息(Package Details)面板中,单击差异(Differences)显示更改。
- 查看更改。
- 单击批准数据包(Approve Package)。
- 可选:输入原因(Reason)。
- 单击批准。
数据包已获得批准,现在将进入队列进行处理。
拒绝导入
要拒绝导入,请执行以下操作:
- 导航至你的来源。
- 按待批准项筛选导入数据列表。
-
从数据包菜单()中,选择查看数据包详细信息(View Package Details)。
- 在数据包详细信息(Package Details)面板中,单击差异(Differences)显示更改。
- 查看更改。
- 单击拒绝数据包(Reject Package)。
- 可选:输入原因(Reason)。
- 单击拒绝。
- 在拒绝数据包(Reject Package)确认对话框中,单击确认(Confirm)。
查看关联对象
可以从数据包详细信息(Package Details)面板的关联对象(Associated Objects)选项卡查看导入数据包的关联对象。该选项卡列出了数据包中的更改可能影响的导出定义、列表和视图。
要访问该选项卡,请打开数据包详细信息(Package Details)面板,然后单击以打开关联对象(Associated Objects)选项卡。
Workbench 在每个已更改表单的表单标签上显示一个更改图标(橙色圆圈)徽章。
对于在清单文件的“表单(form)”属性中映射的任何文件,关联对象选项卡不会显示该导入文件中可能受到影响的任何对象。
查看导入状态
可以从导入(Import)>数据包(Packages)中检查导入数据包的状态。此页面列出了从 Vault EDC 和第三方工具导入的每个数据包的状态。还可以从此页面下载导入数据包和问题日志(错误和警告)。
完成状态:要使导入包进入移至完成导入状态,研究的 Workbench 用户必须打开一个列表。否则,导入将保持进行中状态。如果研究启用了自动交换功能,则不需要进行此操作。所有增量研究和 OpenEDC 研究均默认启用自动交换功能。
没有受限数据访问权限的用户可以下载导入包日志,但无法下载数据文件。具有受限数据访问权限的用户可以下载包含盲态数据的数据包。
筛选
可以使用导入状态筛选器轻松筛选列表,仅显示已完成或失败的导入。单击错误(Error)仅显示失败的导入,或单击完成(Complete)以显示已完成的导入。
再处理
Workbench 会在导入或最后一次重新处理的 24 小时后,自动重新处理包含下列可恢复警告代码的生产环境第三方数据包。
- D-002:未找到研究中心
- D-003:未找到受试者
- D-004:未找到事件
出现这些代码意味着数据文件中的个别行因未匹配到主要来源而无法导入。
Workbench 不会重新处理包含其他警告或错误代码的数据包,因为重新处理仅检测主要来源中新录入的数据,且只有上述警告可通过新录入数据解决。请注意,自动重新处理仅适用于生产环境,不适用于 TST、TRN 或 VAL 环境(即使这些环境出现上述警告)。
Workbench 导入状态
当导入数据包能够导入且仅带警告时,Workbench 会以橙色突出显示状态,以指示存在警告。导入完成后,可以下载问题日志以查看警告。
| 状态 | 描述 |
|---|---|
| 排队 | 数据包位于处理队列中。数据包已进入处理队列。在该数据包之前有一个包含更改的数据包排队,该数据包正在等待已暂停的数据包获得批准或被拒绝。 |
| 已暂停 | CDB 检测到清单中的更改,因此导入被暂停,直到批准或拒绝该数据包。 |
| 已批准 | 清单中的更改已获得批准。CDB 现在将导入数据包。 |
| 已拒绝 | 清单中的更改已被拒绝。 |
| 已跳过 | 数据包被跳过且未导入。在处理数据包之前,已导入该源的另一个数据包。此状态仅适用于第三方数据包。 |
| 进行中 | 此数据包的导入过程已经开始,Workbench 未发现任何错误或警告。 |
| 进行中(带警告) | 导入过程正在进行中,但 Workbench 已发现警告。 |
| 错误 | 导入失败,因为导入包中存在一个或多个错误。下载问题日志并查看错误。 |
| 完成 | Workbench 已成功导入数据包,没有错误或警告。 |
| 完成(带警告) | Workbench 已成功导入数据包,但存在一个或多个警告。下载问题日志并查看警告。 |
| 未导入 | Workbench 跳过了此数据包,因为在处理开始之前上传了同一来源的较新数据包。当数据包进入未导入状态时,Workbench 还会将处理日期替换为“已替换”。 |
| 正在进行重新处理 | Workbench 已开始重新处理此数据包,因为导入了来自其他源的新数据包。 |
| 重新处理完成 | Workbench 完成了对此数据包的重新处理,没有错误或警告。 |
| 重新处理完成(带警告) | Workbench 完成了对此数据包的重新处理,但存在一个或多个警告。下载问题日志并查看警告。 |
| 重新处理错误 | 重新处理失败,因为导入包中存在一个或多个错误。下载问题日志并查看错误。 |
下载导出包
要下载导入包,请执行以下操作:
- 导航到研究 (Study)的导入 (Import)。
- 在来源列表中找到你的来源 (Source)。
- 点击数据表 (Packages) 以打开来源 (Source) 的“数据包”页面。
- 在列表中找到导入数据包。
-
单击数据包链接。
- 从 ZIP 文件夹中提取文件,并在选择的工具中进行查看。
下载日志
可以下载任何导入操作的导入日志(CSV)和失败导入操作的问题日志(CSV)。导入日志列出了有关导入作业和摄取到 Workbench 的数据的详细信息。
导入日志列出了以下信息:
- 转换开始时间
- 转换完成时间
- 转换持续时间
- 导入开始时间
- 导入完成时间
- 导入持续时间
要下载导入日志,请执行以下操作:
- 导航到研究 (Study)的导入 (Import)。
- 在来源列表中找到你的来源 (Source)。
- 点击数据表 (Packages) 以打开来源 (Source) 的“数据包”页面。
- 在列表中找到导入数据包。
- 从数据包 (Package) () 菜单中,选择下载日志 (Download Logs)。
问题日志
问题日志列出了 Workbench 在导入数据包时遇到的所有错误和警告。在此处查看可能的错误和警告列表。
要查看问题日志,请执行以下操作:
- 导航到来源 (Source) 的数据包 (Packages) 页面。
- 在列表中找到导入数据包。
- 从数据包()菜单中,选择查看数据包详细信息(View Package Details)。
- 在数据包详细信息(Package Details)面板中,单击问题(Issues)。
- 可选:在问题日志(Issue Log)面板中,单击下载()以下载日志的 CSV。
要下载问题日志,而不先在应用程序中进行查看,请执行以下操作:
- 导航到来源 (Source) 的数据包 (Packages) 页面。
- 在列表中找到导入数据包。
- 从数据包 (Package) () 菜单中,选择下载日志 (Download Logs)。
查看导入的数据
增量摄取:通过增量摄取功能,UI 会显示最近导入的第三方数据包(无论其导入时间长短),以及过去 30 天内导入的所有第三方数据包。
上传后,Workbench 会为导入包中的每个唯一文件创建一个表单。Workbench 会自动为研究中的每个唯一表单生成核心列表,无论该表单来自 Veeva EDC 还是从第三方系统导入。
这些核心列表的默认 CQL 质疑为:
SELECT @HDR, * from source.filename 在上述实验室导入示例中,CDB 使用以下质疑创建两个核心列表:生化和血液学(每个 CSV 文件一个):
| 生化 |
|
| 血液学 |
|
定义
CDB 为每个 CSV 文件创建一个表单定义,以在 CDB Workbench 应用程序中将导入的数据定义为“表单”。这些记录使用 CSV 文件名(不带扩展名)作为名称,例如,“hematology”。CDB 还会创建一个条目组定义,以便在表单中将数据条目分组在一起。CDB 通过在 CSV 文件名(不带扩展名)前加上“ig_”来命名,例如“ig_hematology”。
这两个定义在列表中显示为一列(form_name 和 ig_name)。可以编辑列表的 CQL 质疑以隐藏这些列。