编码器研究设置
Veeva Coder 中有各种设置可以控制可用功能,例如同义词列表 审查和自动编码范围,可以从编码器工具中进行管理。Veeva Coder 包含应用程序级设置,供 Veeva EDC 用作“模板”并应用于新研究。可以从编码器工具(Coder Tools)> 默认研究设置(Default Study Settings)中自定义这些设置。
然后,可以从编码器工具> 研究设置(Study Settings)中基于每个研究自定义设置。
先决条件
访问编码器工具
若要访问 编码器工具(Coder Tools)管理区域,请单击主导航栏中的工具(Tools)选项卡,然后单击编码器工具。
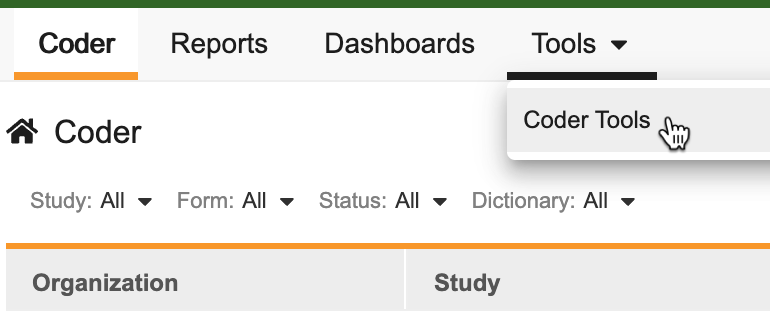
进入编码器工具后,可以单击子选项卡以导航到其中的不同区域。
默认研究设置
可以从编码器工具> 默认研究设置(以前称为应用程序设置)中修改应用程序级别的默认设置。这些设置是 Vault 中每个新 研究 的默认设置。可以从编码器工具> 研究设置中配置单个研究 的设置。

如何编辑默认研究设置
应用程序级设置的更改将应用于 Vault 中所有未来的研究。
要更改应用程序级设置,请执行以下操作:
- 导航到编码器工具> 默认研究设置。
-
单击编辑(Edit)。
-
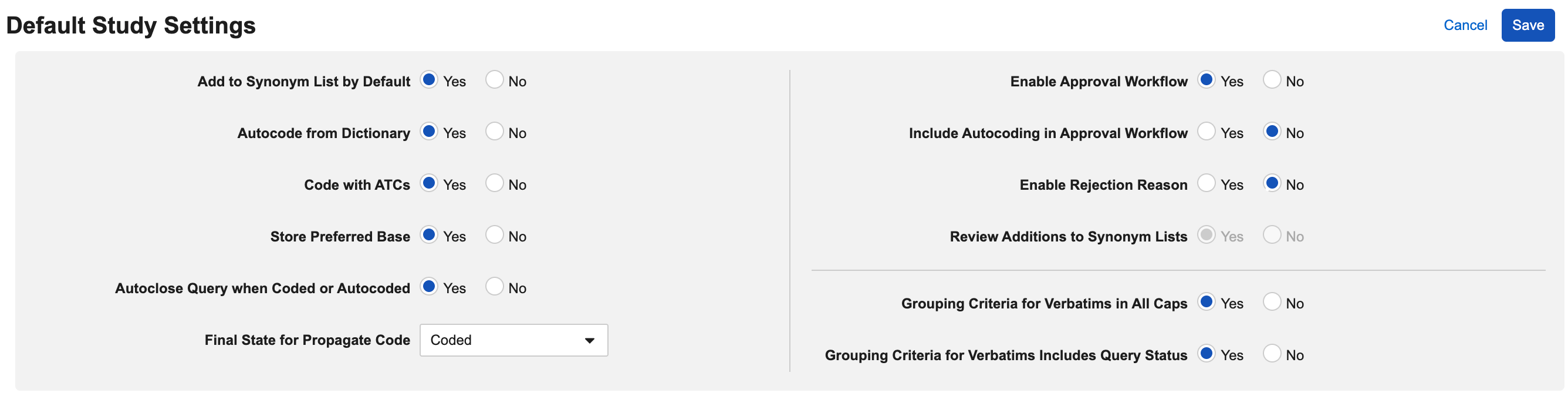
为要更改的每个设置选择是(Yes)或否(No)。请参见下面每个设置的描述。
- 点击 Save(保存)。
研究设置
可以从编码器工具> 研究设置中基于每个研究修改设置。此处的更改仅适用于所选的研究。默认情况下,研究级别的设置选择与应用程序级别的设置匹配。
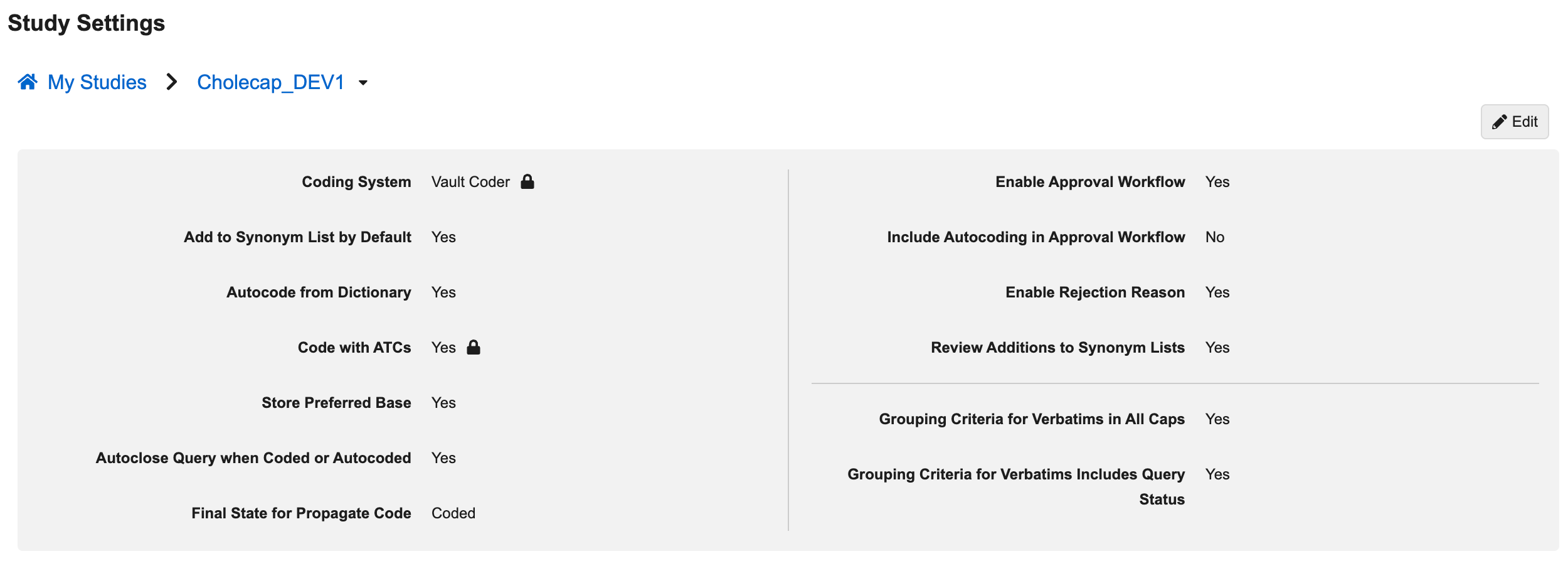
从编码器工具> 研究设置中,还可以执行以下操作:
- 分配医学编码停止列表和同义词列表。有关详细信息,请参见“编码器工具中的表单配置”。
- 更新表单 版本。有关详细信息,请参见“更新到新词典版本”。
如何编辑研究设置
如果更改了编码器工具 > 研究设置中的设置,Veeva Coder 会立即应用已更新的设置。在某项研究 的编码开始进行后更新设置时要小心。
要编辑研究级别的设置,请执行以下操作:
- 导航到编码器工具> 研究设置(Study Settings)。
- 使用研究选择器 来选择研究:
- 在搜索研究(Search Studies)字段中键入研究的名称。
- 单击研究以将其选中。
-
单击编辑。
-
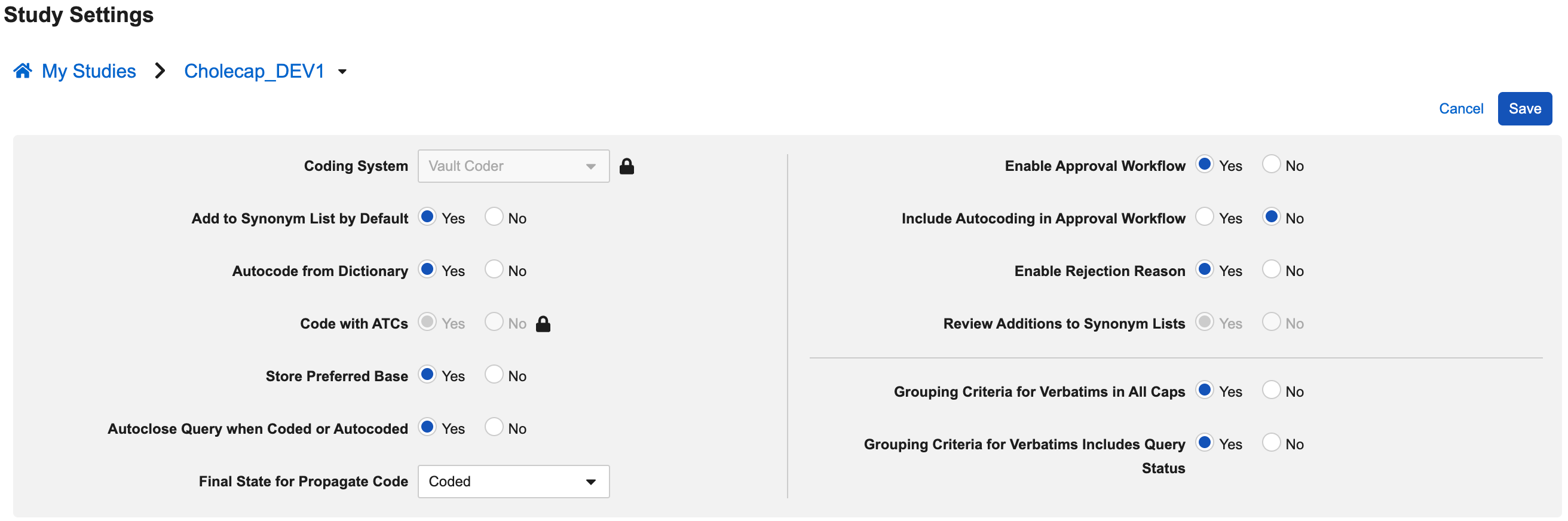
为要更改的每个设置选择是(Yes)或否(No)。请参见下面每个设置的描述。
- 点击 Save(保存)。
可用设置
提供以下十一(11)种设置:
- 编码系统
- 默认添加到同义词列表
- 审查同义词列表的添加内容
- 从词典自动编码
- 使用 ATC 进行编码
- 存储物质基础
- 编码或自动编码时自动关闭质疑
- 传播代码的最终状态
- 启用批准工作流
- 将自动编码纳入审批工作流
- 启用拒绝原因
- 逐字记录分组标准全部大写
- 逐字记录分组标准包括质疑状态
在 21R1(2021 年 4 月)版本中,作为“编码员批准工作流”功能的一部分,移除了自动编码的编码请求需要审查设置。
编码系统
编码系统(Coding System)设置用于控制是使用 Veeva Coder 还是第三方系统进行临床编码活动。默认情况下,此设置已设为 Veeva Coder。要使用第三方系统,请为此设置选择第三方系统。与 Veeva 服务代表和贵组织的开发团队合作,创建 Veeva EDC 与所选编码系统之间的集成,以对 EDC 数据进行编码。
默认添加到同义词列表
默认添加到同义词列表(Add to Synonym Lists by Default)设置用于控制 Veeva EDC 是否自动为研究 生成同义词列表。
| 选择 | 默认设置 | 影响 |
|---|---|---|
| 是(Yes) | 在编码员编码时,默认情况下,Veeva EDC 会将同义词 添加到同义词列表 中。编码员在编码时可以选择不添加到同义词列表。 | |
| 否(No) | Veeva EDC 不会生成同义词列表。必须手动创建同义词列表,编码员必须选择添加到同义词列表。 |
从词典自动编码
除了同义词列表 之外,从词典自动编码(Autocode from Dictionary)设置也用于控制 Veeva Coder 是否从编码词典进行自动编码。
| 选择 | 默认设置 | 影响 |
|---|---|---|
| 是(Yes) | Veeva Coder 从同义词列表 和词典进行自动编码。Veeva Coder 首先尝试从同义词列表 中进行自动编码。如果没有匹配项,Veeva Coder 会尝试在编码词典中查找匹配项。 | |
| 否(No) | Veeva Coder 仅基于同义词列表(不是来自词典)进行自动编码。 |
使用 ATC 进行编码
使用 ATC 进行编码(Code With ATCs)设置用于控制 Veeva Coder 在编码期间是否存储 WHODrug 编码请求 的 ATC。一些用户更喜欢不使用 ATC 进行编码,因为他们没有使用 ATC 进行编码,或者认为 ATC 不会为他们的分析提供任何附加值。
一旦至少有一个编码请求 具有已分配的编码,Veeva EDC 就会为研究 锁定此设置。
| 选择 | 默认设置 | 影响 |
|---|---|---|
| 是(Yes) | Veeva Coder 会在编码期间存储 WHODrug 编码请求 的 ATC。编码时,ATC 列将显示在词典面板中,并存储在编码请求上。 | |
| 否(No) | Veeva Coder 不会在编码期间存储 WHODrug 编码请求 的 ATC。编码时,ATC 列不显示在词典面板中,也不存储在编码请求上。 |
存储物质基础
存储物质基础(Store Substance Base)设置用于控制 Veeva Coder 是否存储 WHODrug B3 和 C3 术语的物质基础 列。
| 选择项 | 默认 | 影响 |
|---|---|---|
| 是 | (对于 21R1 之后创建的研究) |
Veeva Coder 存储 WHODrug 编码请求 的物质基础,并在提取中包含物质基础。 |
| 否 | (对于 21R1 之前创建的研究) |
Veeva Coder 不存储物质基础。 |
编码或自动编码时自动关闭质疑
编码或自动编码时自动关闭质疑(Autoclose Query when coded or autocoded)研究设置用于控制当已质疑编码请求的编码状态更改为“已编码(Coded)”或“已自动编码(Autocoded)”时是否让质疑自动关闭。
| 选择 | 默认设置 | 影响 |
|---|---|---|
| 是 | 当质疑的编码请求 的编码状态 更改为已编码或已自动编码时,质疑将自动关闭。 | |
| 否 | 当质疑的编码请求 的编码状态 更改为已编码或已自动编码时,质疑不会自动关闭。 |
传播编码的最终状态
传播编码的最终状态(Final State for Propagate Code)研究设置用于控制通过传播编码编码的编码请求的编码状态。
| 选择 | 默认设置 | 影响 |
|---|---|---|
| 已编码 | 当启用批准工作流(Enable Approval Workflow)研究设置设为是(Yes)时,“传播编码”功能会将主要选择的编码状态 和所有不区分大小写、精确匹配的编码请求 更新为已编码,在启用批准工作流(Enable Approval Workflow)研究设置设为否(No)的情况下,会更新为等待批准。 | |
| 已自动编码 | 当启用批准工作流(Enable Approval Workflow)研究设置设为是(Yes)时,“传播编码”功能会将主要选择的编码状态 和所有不区分大小写、精确匹配的编码请求 更新为已自动编码,在启用批准工作流(Enable Approval Workflow)研究设置设为否(No)的情况下,会更新为等待批准。 |
启用批准工作流
启用批准工作流(Enable Approval Workflow)功能用于控制研究 是否使用“编码员批准工作流”功能。
| 选择 | 默认设置 | 影响 |
|---|---|---|
| 是 | 该研究 使用“编码员批准工作流”功能。编码员将编码分配给编码请求 后,它将进入待批准 状态,编码器管理员必须先批准编码,然后该请求才会进入已编码 状态。 | |
| 否 | 该研究 不会使用“编码员批准工作流”功能。当编码员将编码分配给编码请求 时,该请求将直接进入已编码 状态。 |
将自动编码纳入审批工作流
将自动编码纳入审批工作流这一设置用于控制 Veeva Coder 是否将经过自动编码的编码请求 纳入编码员批准工作流。仅当启用批准工作流(Enable Approval Workflow)设为是(Yes)时,此选项才可用。
| 选择 | 默认设置 | 影响 |
|---|---|---|
| 是(Yes) | 当逐字记录通过同义词列表或词典(根据研究设置)进行自动编码时,Veeva Coder 会将编码请求 移至等待批准 状态,并将其纳入审批工作流。 | |
| 否(No) | 经过自动编码的编码请求 会被移至已自动编码 状态,且不会被纳入审批工作流。 |
启用拒绝原因
作为编码员批准工作流的一部分,启用拒绝原因(Enable Rejection Reason)功能用于控制 Veeva Coder 是否在编码请求 上将拒绝原因作为备注 发布。仅当启用批准工作流(Enable Approval Workflow)设为是(Yes)时,此选项才可用。
| 选择 | 默认设置 | 影响 |
|---|---|---|
| 是(Yes) | 当编码器管理员拒绝分配的编码时,Veeva Coder 会在编码请求 上发布一条备注,其中包含提供的拒绝原因,同时将请求移至已拒绝 状态。 | |
| 否 | 当编码器管理拒绝已分配的编码时,编码请求 将进入已拒绝 状态,但 Veeva Coder 不会发布备注。 |
审查同义词列表的添加内容
审查同义词列表的添加内容(Review Additions to Synonym Lists)设置用于控制在编码员分配编码后,当添加到同义词列表切换为 Y(是)时,系统是否自动将同义词 添加到同义词列表。
| 选择 | 默认设置 | 影响 |
|---|---|---|
| 是 | 可以审查和批准(或者拒绝或删除)同义词,然后再将其用于为自动编码和建议提供信息参考。在审查同义词 之前,它们仍处于待审查 状态。如果已有同名的同义词 记录,包括适应症 和途径(对于 WHODrug),并且该同义词 处于活动 状态或待审查 状态,则 Veeva Coder 不会添加新的同义词 以供审查。如果没有精确匹配项,或者精确匹配项被拒绝,Veeva Coder 会创建一个新的同义词(处于待审查 状态)以供审查。 | |
| 否(No) | Veeva Coder 会自动批准同义词 并将其添加到同义词列表 中,然后立即使用它们为自动编码和建议提供信息参考。Veeva Coder 首先在现有同义词(包括 WHODrug 的适应症 和途径)中检查逐字记录是否存在精确匹配项。如果存在精确匹配项,Veeva Coder 不会创建其他同义词 记录。如果不存在精确匹配项,Veeva Coder 会在活动 状态下创建新的同义词 记录。 |
逐字记录分组标准全部大写
逐字记录分组标准全部大写(Grouping Criteria for Verbatims in All Caps)研究设置用于控制是否在“列表视图”、“组视图”和“属性面板”中全部大写的形式显示逐字记录并进行分组。
| 选择 | 默认设置 | 影响 |
|---|---|---|
| 是 | 逐字记录以全部大写的形式显示在“列表视图”、“组视图”和“属性面板”中并进行分组。 | |
| 否 | 逐字记录不以全部大写的形式进行显示和分组。 |
逐字记录分组标准包括质疑状态
逐字记录分组标准包括质疑状态(Grouping Criteria for Verbatims Includes Query Status)功能用于控制在对编码请求 进行分组以进行分组质疑时,Veeva Coder 是否在分组标准中包括质疑状态。
| 选择 | 默认设置 | 影响 |
|---|---|---|
| 是(Yes) | (对于 21R1 之后创建的研究) |
Veeva Coder 会在用于对编码请求 进行分组的分组标准中包括质疑状态。 |
| 否(No) | (对于 21R1 之前创建的研究) |
Veeva Coder 不会在分组标准中包括质疑状态,而是按逐字记录、编码状态和已分配编码以及适应症、途径 和严重性(如果适用)对编码请求 进行分组。 |