Study File Format API
The Study File Format (SFF) is a standardized method of exporting clinical data from Veeva EDC and Clinical Reporting systems. SFF is accessed through the Study File Format API and comes as a single ZIP package that includes two main parts: the Study Data and the Study Definition.
SFF is useful for reporting on clinical and operational data and for integrating with other systems. The ZIP package contains a manifest file and CSVs that provide clinical, operational, and reference data. The manifest file details the relationship between the Study Definition and the Study Data.
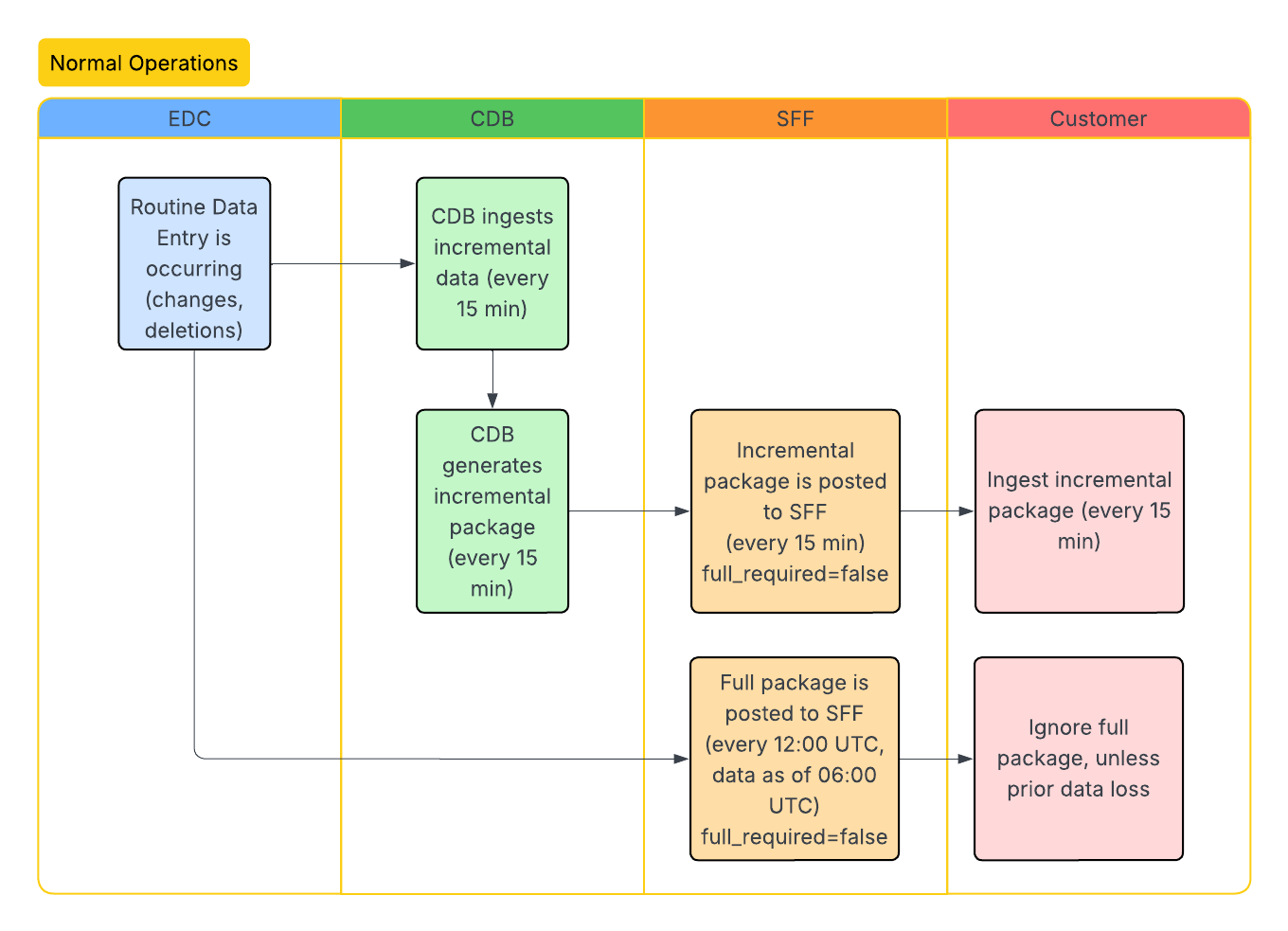
Extraction Types: There are two types of SFF extraction, full and incremental. A full SFF extraction contains the entire dataset, from the start of data collection up to the latest SFF full extraction run. Full SFF extractions (packages) are available every 24 hours at 12:00 PM UTC. Clinical and operational data can be generated incrementally to reflect any changes since the latest SFF extraction. You can specify full or incremental when using the List Packages endpoint.
Enablement: The EDC license includes both full and incremental SFF packages. You can enable full packages in EDC Tools > Study Settings. Contact Veeva Support to enable incremental packages.
Versioning: SFF uses separate versioning for its API and packages. We maintain two active API versions and two active package versions. For package versioning, we only create a new version when there are schema changes that could break existing integrations. For example, we don’t version the package if we only add a column to the CSV file that doesn’t impact the structure. We do create a new version if the manifest attributes are altered.
Learn more about API versioning on the Developer Portal.
Prerequisites
Users with the standard CDMS Super User study role can perform the actions described below by default. If your organization uses custom roles, then your role must grant the following permission:
| Type | Permission Label | Controls |
|---|---|---|
| Functional Permission | Study File Format API Access | Ability to access and use the Study File Format API. Study File Format API Access provides API Access and Restricted Data Access by default. For EDC studies, users do not need the Clinical Reporting Tab permission to access SFF. |
Enabling Study File Format API
You can only enable SFF in production study environments.
To enable the Study File Format feature in your vault:
-
Navigate to Tools > EDC Tools > Study Settings for your Study.

- Click Edit.
- Click Yes to Enable Study File Format API.
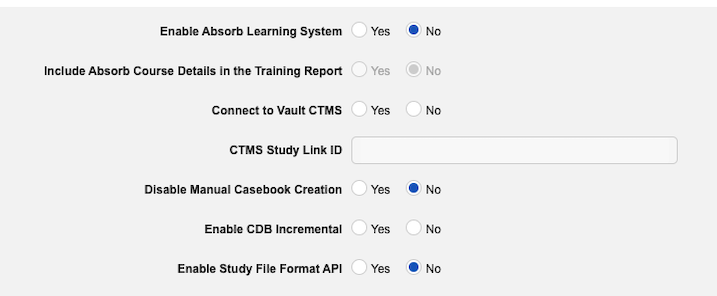
If you’re enabling SFF for the first time, wait until the first full SFF package is published and available through the API. This also applies if you disable the feature and then re-enable it for a Study.
Clinical Reporting customers already have incremental extraction enabled by default.
Package Contents & Organization
SFF packages are provided in a ZIP file format. Inside the ZIP file, there is a folder named data that contains all the CSV files. In the root of the ZIP file, the “manifest.json” file contains the self-describing structure of the package, as well as the Study Design information.
The package file name format is as follows:
Study Name_SFF_Full/Incremental_YYYY_MM_DD_HH_MM_SS
For example, Natevba_SFF_Incremental_2024_08_16_00_30_00
The timestamp provided in the name indicates the publication time of the package.
Duplicate Column Headers
Duplicate CSV column headers appear when Item Definitions are reused on a form. SFF addresses duplication by appending an “_n” for each duplicate column. For example, _1, _2. The first column maintains the original name, and each successive column receives an appended suffix. Column name deduplication is case sensitive. For example, “ColumnName” and “columnname” are treated as different names and are not deduplicated.
Every instance of a column’s appearance displays in the clinical_data section of the manifest file. In this section, the deduplicated name shows in the name field, and the original Item Definition name shows in the lookup_name field.
With deduplication, the itemgroups array becomes a single attribute, showing the single Item Group Definition for each column. This also applies to Local Labs’ column headers when multiple lab panels exist on a form definition.
Package version 2.0 supports duplicate column functionality.
Full Data Extraction
Full extraction of the ZIP package is available every 24 hours and is designed to help you update your downstream systems in situations such as:
- Enabling SFF for a Study for the first time
- During a new study design change or deployment
- Replacing your data with a full refresh (i.e., a full ingestion of data from EDC into CDB)
- Encountering a critical error that requires a restart
Full Publication Timing: Starting in 26R1, CDMS publishes full SFF packages based on the vault’s configured timezone rather than UTC (although, the system still records timestamps in UTC). You may receive two full packages on the day the timezone transitions or if you modify the vault’s timezone in the future.
Study Design Data
Study design data in the manifest file is always extracted as a full dataset, not incrementally. The latest version of the study design data is captured with each extraction.
Labels and Override Labels
Labels and override labels include data from the latest study design version.
Incremental Data Extraction
Incremental extraction is available every 15 minutes. When using incremental extraction, if there are no changes between the last extract and the current extract, the file will be generated as a blank file with column headers only.
Deletes File
The Deletes CSV file is included in the incremental extraction’s reference data. It includes all deleted data necessary to identify which rows should be removed from your integrated systems.
Row ID Column
The Row ID column is included in every file, except the Deletes file, and can be used to identify updated and deleted rows. It consists of the Row ID, an underlying identifier used to create a unique row of data. The Row ID structure varies across files.
Handling Data Changes
You should treat any changes to the incremental extraction or ZIP package as an Upsert versus an Insert. An Upsert command updates an existing row if the value already exists, or inserts a new row if it doesn’t. The only exception to this is the Deletes file, which tracks deleted rows.
Understanding the Manifest File
JSON is a structured format that can be used to map study design objects to Study Data. The manifest.json file allows users to consume data in a programmatic way. It defines the Study Data file structure and includes the study design.
The header information in the manifest file consists of the following:
- Study name
- Documentation URL
- SFF version
- Extract name
- Creation datetime
- Number of files in the package
- Whether the clinical data is incrementally generated or not
- What study design version the manifest refers to
The SFF API version operates independently from the SFF package version. For example, the SFF API version may be available in versions 23.2, 24.3, and 25.2, while the SFF package offers 1.0 and 2.0 versions.
The data is divided into four JSON code blocks:
- Operational Data
- Reference Data
- Clinical Data
- Study Design
Example Manifest File
Download an example manifest file.
Package Version 1.0:
Package Version 2.0:
Operational & Reference Data
Operational data defines operational data files, including system files, and reference data defines the reference data files associated with the Study.
Clinical Data
Clinical data consists of the filename, source, form, and column headers:
| Field | Description |
|---|---|
| Filename | Name of the CSV file (for example, “prescreening.csv”) |
| Source | The source of the clinical data file (for example, “EDC”) |
| Form | Name of the form definition |
| Columns | The array of file columns includes both pre-defined header columns and clinical item columns. Each item column represents a single Item Definition. Item Definition metadata is derived from EDC Studio. Items may have additional attributes, which are detailed in the Additional Item Attributes section below. |
Additional Item Attributes
The following are examples of additional item attributes for clinical data in the manifest file:
- Name: Name of the attribute
- External_id: External ID of the attribute
- SDTM_name: SDTM name
- Datatype: Based on EDC data types (see section below)
- Length: Populated for text, number, codelist, and unit item types
- Precision: Populated for number and unit item types
- Unknown: Can be populated for date or datetime Item Definitions that allow for unknown parts
- Mask: Typically populated for unknown dates and datetimes
- Item_type: For example, edc__v, derived__v, read_only__v
- Itemgroups: Item Group Definition name(s)
- If an Item Definition is reused across Item Group Definitions, all Item Group Definitions appear in the array in the order they are listed on the Form Definition
- Restricted: Restricted data, the boolean value equals true or false
- Codelist: Codelist Definition name
- Unit: Unit definition name
Datatype
Datatype item attributes are based on the following EDC data types:
- text
- codelist
- url
- label
- boolean
- number
- unit
- date
- datetime
- time
Study Design
The study design (study_design) block includes the following sections:
- Eventgroups: Defines all of the Event Group Definitions configured in the Study
- Events: Defines all of the Event Definitions configured in the Study
- Forms: Defines all of the Form Definitions configured in the Study
- Itemgroups: Defines all of the Item Group Definitions configured in the Study
- Codelists: Defines all of the Codelist Definitions used in the clinical data files (non-labs)
- Units: Defines all of the Unit Definitions used in the clinical data files (non-labs)
- Subject_groups: Defines all of the Subject Group Definitions configured in the Study
Information about each clinical item on a form is found within the clinical data JSON block of the manifest file. For each clinical file, there are reference keys to the Event Group, Event, and Form Definition names. This allows you to map the relationships between the clinical files and the study design objects.
The columns in the manifest file are not guaranteed to be in order. However, you can programmatically map each column to its corresponding CSV column header, which is preserved in order.
Study Data Files
The Study Data portion of SFF also consists of clinical, operational, and reference data. Clinical data files include header columns that indicate the Study, Site Country, Site, Event Group, Event, and Form associated with each subject. Each clinical item on a form will have its own column, positioned after the primary column headers.
Study Data files contain restricted data. The Study File Format API Access permission grants Restricted Data Access permission by default.
Names are typically used over labels for objects such as Event Group, Event, Form, Item Group, Item Definitions and Statuses. Labels can be found in the LABELS CSV file in the full SFF ZIP package. IDs are not visible in the SFF except as the Row ID, which is the unique identifier for a row of data.
Clinical Data Files
The clinical data files consist of one CSV file for each Form Definition. The title of the file is the same as the Form Definition Name. If there are multiple form definitions with the same name, the additional form definitions will have _2, _3, and so on appended to the file name. The order is determined by an alphabetical sort of both the Source Name and the Form Definition Name. Each file contains records representing a row of clinical data for a specific form instance. Clinical data includes forms in the Submitted and In Edit (in_progress_post_submit__v) status.
Clinical Data Headers
The clinical data headers are standard columns that represent the hierarchy of the clinical data within the form. The headers are common across all of the clinical data files.
The list of columns are as follows:
| Column | Data Type | Description |
|---|---|---|
| STUDYNAME | text | Study Name |
| SITECOUNTRY | text | Study Site Three-Letter Country Abbreviation |
| SITENUM | text | Site Number |
| SUBJID | text | Subject Name |
| EGROUPNAME | text | Event Group Name |
| EGSEQ | number | Event Group Sequence |
| EVENTNAME | text | Event Name |
| FORMNAME | text | Form Name |
| FSEQ | number | Form Sequence |
| IGSEQ | number | Item Group Sequence |
| FORMSTATUS | text | Form Status |
| CREATEDDT | datetime | Datetime Form Created |
| FIRSTSUBMITDT | datetime | Datetime Form First Submitted |
| LASTSUBMITDT | datetime | Datetime Form Last Submitted |
| FORMLASTMODDT | datetime | Datetime Form Last Modified |
| Item Columns | varies | Item Columns (expands for the number of items on the form) |
| ROWWRITEDT | datetime | Datetime the row was written to the file |
| ROWID | text | Row ID |
Clinical Item Data
Clinical Items appear after the header columns listed above for each clinical file, with each Item Definition Name in its own column. Data is dynamically added when necessary. For example, if an Item Group is non-repeating, the corresponding Item Group sequence will not be displayed in the clinical form.
Data Types & Formatting
| Data Type | Format | Description |
|---|---|---|
| Text | String | For clinical data items, text can be represented as a codelist or URL data type. Statuses are represented with the name value. For example: submitted__v |
| Number | Digit | Defined precision and/or length |
| Dates | System dates are formatted as YYYY-MM-DD. Each clinical date has two columns: the Derived/ISO8601 Date and the RAW Date as entered. | There are two columns for each date, the derived ISO8601 format, and the RAW format. For example: BIRTHDT: 1990-01-25 and BIRTHDT_RAW: 25-Jan-1990 |
| Datetimes | System datetimes have a UTC timezone. Each clinical datetime has two columns: the Derived/ISO8601 Datetime and the RAW Datetime as entered. | There are two columns for each datetime, the derived ISO8601 format, and the RAW format. For example: LBDTC: 2021-01-01T12:00:00 and BIRTHDT_RAW: 01-Jan-2021 12:00:00: |
| Times | HH:mm:ss | Standard format, ISO8601 |
| Unknowns | For a date with an unknown day, the derived date format is 2024-06-01, and the RAW date format is UN-Jun-2024. For a datetime with an unknown day, the derived datetime format is 2024-06-01T00:00:00, and the RAW datetime format is UN-Jun-2024 UN:UN:UN. For a date with an unknown month + day, the derived date format is 2024-01-01, and the RAW date format is UN-UNK-2024. For a datetime with an unknown month + day, the derived datetime format is2024-01-01T00:00:00, and the RAW datetime format is UN-Jun-2024 UN-UNK-2024 UN:UN:UN. For an unknown time, the derived date format is 2024-06-02T00:00:00, and the RAW date format is 02-Jun-2024 UN:UN:UN. | The manner in which RAW date and datetime outputs represent unknown dates and datetimes. For the Derived date and datetime, the system will default the unknown portion (Month, Day, or Time) to January 1 at 00:00:00 UTC. |
| Booleans | True/False | |
| Units | (item)_UOM (item)_TRANSLATED (item)_UOM_TRANSLATED | For each unit item, there is the unit value, translated value, and the translated unit value. These are denoted by appending suffixes to the clinical item name. The unit of measure (UOM) and translated unit of measure display the unit label. |
| Codelists | (item) (item)_DECODE | The code value is the item value. The DECODE or label is a secondary column dynamically added with a suffix appended to the item name. For example: ethnicity_DECODE |
Operational & System Datasets
Along with clinical data, the SFF ZIP package contains several system datasets that contain operational data.
System datasets provide data related to specific EDC objects and track the progress of all subjects within the Study. They are automatically included in the ZIP package and include the following files:
- SYS_EVENTS.csv
- SYS_FORMS.csv
- SYS_SUBJECTS.csv
- SYS_ILB.csv
- SYS_LINKS.csv
- SYS_SITES.csv
- QUERIES.csv
- QUERY_MSGS.csv
SYS_EVENTS
The SYS_EVENTS dataset describes the Event and Event Group associated with a particular subject, along with their current statuses and change reasons.
It contains the following Event Statuses:
- blank__v (Blank)
- submitted__v (Submitted)
- in_progress__v (In Progress)
- planned__v (Planned)
- did_not_occur__v (Did Not Occur)
The list of SYS_EVENTS columns is as follows:
| Column | Data Type | Description |
|---|---|---|
| STUDYNAME | text | Study Name |
| SITECOUNTRY | text | Study Site Three-Letter Country Abbreviation |
| SITENUM | text | Site Number |
| SUBJID | text | Subject Name |
| EGROUPNAME | text | Event Group Name |
| EGROUPORDER | number | Event Group Order |
| EGSEQ | number | Event Group Sequence |
| EVENTNAME | text | Event Name |
| EVENTORDER | number | Event Order |
| EVENTDT | date | Event Date |
| VISMETHOD | text | Visit Method |
| PLANNEDDT | date | Planned Date |
| OVERDUEDT | date | Event Overdue Date |
| EVENTSTATUS | text | Event Status |
| EVENTRESTRICTED | boolean | Event Restricted |
| CHANGEREASON | text | Event Change Reason |
| EXPFORMS | number | Expected Number of Forms |
| FROZEN | boolean | Event Frozen |
| FROZENDT | datetime | Datetime Event is Frozen |
| LOCKED | boolean | Event Locked |
| LOCKEDDT | datetime | Datetime Event is Locked |
| SIGNED | boolean | Event Signed |
| SIGNEDDT | datetime | Datetime Event is Signed |
| EVENTDTLASTMODDT | datetime | Event Date Last Modified Datetime |
| SYSID | text | The primary ID of the system file (VoF ID for EDC data or the source system ID for third-party data) |
| SOURCE | text | The source of the data |
| ROWWRITEDT | datetime | Datetime the row is written to the file |
| ROWID | text | Row ID |
SYS_FORMS
The SYS_FORMS dataset offers an overview of all forms containing subject data, including form status, form-level review statuses for SDV and DMR, and form-level ILB (Intentionally Left Blank) information.
It contains the following Form Statuses:
- blank__v (Blank)
- submitted__v (Submitted)
- in_progress__v (In Progress)
- in_progress_post_submit__v (In Edit)
The list of SYS_FORMS columns are as follows:
| Column | Data Type | Description |
|---|---|---|
| STUDYNAME | text | Study Name |
| SITECOUNTRY | text | Study Site Three-Letter Country Abbreviation |
| SITENUM | text | Site Number |
| SUBJID | text | Subject Name |
| EGROUPNAME | text | Event Group Name |
| EGSEQ | number | Event Group Sequence |
| EVENTNAME | text | Event Name |
| FORMNAME | text | Form Name |
| FSEQ | number | Form Sequence |
| FORMSTATUS | text | Form Status |
| FORMRESTRICTED | boolean | Form Restricted |
| CREATEDDT | datetime | Form Created Date |
| FIRSTSUBMITDT | datetime | Form First Submit Date |
| LASTSUBMITDT | datetime | Form Last Submit Date |
| NUMSUBMITS | number | Number of Form Submits |
| OVERDUEDT | date | Form Overdue Date |
| CHANGEREASON | text | Form Change Reason |
| SDVOVRPLAN | text | SDV Override Plan |
| SDVREQ | boolean | SDV Required |
| SDVCOMP | boolean | SDV Completed |
| FIRSTSDVDT | datetime | First SDV Date |
| SDVCOMPDT | datetime | SDV Completed Datetime |
| SDVUSERMODDT | datetime | SDV User Modified Date |
| DMROVRPLAN | text | DMR Override Plan |
| DMRREQ | boolean | DMR Required |
| DMRCOMP | boolean | DMR Completed |
| FIRSTDMRDT | datetime | First DMR Date |
| DMRCOMPDT | datetime | DMR Completed Datetime |
| DMRUSERMODDT | datetime | DMR User Modified Date |
| FROZEN | boolean | Form Frozen |
| FROZENDT | datetime | Datetime Form is Frozen |
| LOCKED | boolean | Form Locked |
| LOCKEDDT | datetime | Datetime Form is Locked |
| SIGNED | boolean | Form Signed |
| SIGNEDDT | datetime | Datetime Form is Signed |
| ILB | boolean | Form Intentionally Left Blank |
| ILBREASON | text | Reason for Form Intentionally Left Blank |
| FORMLASTMODBY | text | Form Last Modified By |
| FORMLASTMODDT | datetime | Form Last Modified Datetime |
| SYSID | text | The primary ID of the system file (VoF ID for EDC data or the source system ID for third-party data) |
| SOURCE | text | The source of the data |
| ROWWRITEDT | datetime | Datetime the row is written to the file |
| ROWID | text | Row ID |
SYS_SUBJECTS
The SYS_SUBJECTS dataset contains data related to the subjects within the Study.
The list of SYS_SUBJECTS columns are as follows:
| Column | Data Type | Description |
|---|---|---|
| CASEBOOKVER | number | Subject’s Casebook Version Number |
| STUDYNAME | text | Study Name |
| SITECOUNTRY | text | Study Site Three-Letter Country Abbreviation |
| SITENUM | text | Site Number |
| SUBJID | text | Subject Name |
| SUBSTATUS | text | Subject Status |
| SUBRESTRICTED | boolean | Subject Restricted |
| SDVPLAN | text | SDV Plan assigned to the Subject |
| DMRPLAN | text | DMR Plan assigned to the Subject |
| FROZEN | boolean | Subject Frozen |
| LOCKED | boolean | Subject Locked |
| SIGNED | boolean | Subject Signed |
| LATESTARM | text | Latest Arm |
| LATESTCOHORT | text | Latest Cohort |
| LATESTSUBSTUDY | text | Latest Substudy |
| CNSNTDT | date | Initial Consent Date |
| SCRDDT | date | Screened Date |
| SCRFAILDT | date | Screen Failed Date |
| ENRDDT | date | Enrolled Date |
| RDMDDT | date | Randomized Date |
| STARTTRTDT | date | Started Treatment Date |
| ENDTRTDT | date | End Treatment Date |
| WTHDRWNDT | date | Withdrawn Date |
| STARTFLLWUPDT | date | Started Follow Up Date |
| LOSTFLLWUPDT | date | Lost to Follow Up Date |
| CMPLTDT | date | End of Study Date |
| SUBLASTMODBY | text | Subject Last Modified By |
| SUBLASTMODDT | datetime | Subject Last Modified Datetime |
| SYSID | text | The primary ID of the system file (VoF ID for EDC data or the source system ID for third-party data) |
| SOURCE | text | The source of the data |
| ROWWRITEDT | datetime | Datetime that the row was written to the file |
| ROWID | text | Row ID |
SYS_ILB
The SYS_ILB dataset contains Intentionally Left Blank data for relevant items on a particular form for each subject across all study sites. It includes data in the Submitted status.
The list of SYS_ILB columns are as follows:
| Column | Data Type | Description |
|---|---|---|
| STUDYNAME | text | Study Name |
| SITECOUNTRY | text | Study Site Three-Letter Country Abbreviation |
| SITENUM | text | Site Number |
| SUBJID | text | Subject Name |
| EGROUPNAME | text | Event Group Name |
| EGSEQ | number | Event Group Sequence |
| EVENTNAME | text | Event Name |
| FORMNAME | text | Form Name |
| FSEQ | number | Form Sequence |
| IGROUPNAME | text | Item Group Name |
| IGSEQ | number | Item Group Sequence |
| ITEMNAME | text | Item Name |
| ILBREASON | text | Intentionally Left Blank Reason |
| SOURCE | text | The source of the data |
| ROWWRITEDT | datetime | Datetime the row is written to the file |
| ROWID | text | Row ID |
SYS_LINKS
The SYS_LINKS dataset contains information regarding any links added to the clinical data for form-to-form linking and item-to-form linking.
The list of SYS_LINKS columns are as follows:
| Column | Data Type | Description |
|---|---|---|
| STUDYNAME | text | Study Name |
| SITECOUNTRY | text | Study Site Three-Letter Country Abbreviation |
| SITENUM | text | Site Number |
| SUBJID | text | Subject Name |
| EGROUPNAME | text | Event Group Name |
| EGSEQ | number | Event Group Sequence |
| EVENTNAME | text | Event Name |
| FORMNAME | text | Form Name |
| FSEQ | number | Form Sequence |
| IGROUPNAME | text | Item Group Definition Name |
| IGSEQ | number | Item Group Sequence |
| FORMLINKNAME | text | Form Link Item Definition Name |
| LINKID | text | Link Vault ID |
| LINKCREATEDBY | text | Link Created By |
| LINKCREATEDDT | datetime | Link Created Datetime |
| FORMID | text | Form execution ID |
| SOURCE | text | The source of the data |
| ROWWRITEDT | datetime | Datetime the row is written to the file |
| ROWID | text | Row ID |
SYS_SITES
This dataset contains data about Study Sites.
The list of SYS_SITES columns are as follows:
| Column | Data Type | Description |
|---|---|---|
| STUDYNAME | text | Study Name |
| SITECOUNTRY | text | Study Site Three-Letter Country Abbreviation |
| SITENUM | text | Site Number |
| SITENAME | text | Site Name |
| SITEPI | text | Site Principal Investigator |
| SITESTATUS | text | Site Status |
| SITETIMEZONE | text | Site Timezone |
| SYSID | text | The primary ID of the system file (VoF ID for EDC data or the source system ID for third-party data) |
| SOURCE | text | The source of the data |
| ROWWRITEDT | datetime | Datetime the row is written to the file |
| ROWID | text | Row ID |
Queries File
The Queries file contains a record of each query created in the Study, along with operational metrics such as when the query was opened, when it was closed, and who created it. You can use this data to calculate additional metrics for downstream reporting and analytics.
The list of columns in the Queries file are as follows:
| Column | Data Type | Description |
|---|---|---|
| STUDYNAME | text | Study Name |
| SITECOUNTRY | text | Study Site Three-Letter Country Abbreviation |
| SITENUM | text | Site Number |
| SUBJID | text | Subject Name |
| EGROUPNAME | text | Event Group Name |
| EGSEQ | number | Event Group Sequence |
| EVENTNAME | text | Event Name |
| EVENTDT | date | Event Date |
| EVENTSTATUS | text | Event Status |
| FORMNAME | text | Form Name |
| FSEQ | number | Form Sequence |
| IGROUPNAME | text | Item Group Name |
| IGSEQ | number | Item Group Sequence |
| ITEMNAME | text | Item Name |
| QUERYNAME | text | Query Name |
| QUERYID | text | Query ID |
| ORIGINSYS | text | Originating System |
| ORIGINID | text | Originating ID |
| ORIGINNAME | text | Originating Name |
| QUERYSTATUS | text | Query Status |
| QUERYTYPE | text | Query Type |
| QUERYRESTRICTED | boolean | Restricted Query |
| MANUALQUERY | boolean | Manual or System Query |
| RULEDEF | text | Rule Definition Name |
| TRIGID | text | Trigger Name |
| FIRSTQUERYMSG | text | First Query Message |
| QUERYTEAM | text | Query Team |
| QUERYROWEXTERNALID | text | Query Row External ID (Populated for queries on Non-Veeva EDC data if set) |
| QUERYCREATEDBY | text | Query Created By |
| QUERYCREATEDDT | datetime | Query Created Datetime |
| QUERYLASTCLOSEDDT | datetime | Query Last Closed Datetime |
| ORIGINUSER | text | The user who originated the query |
| ROWWRITEDT | datetime | Datetime the row is written to the file |
| ROWID | text | Row ID |
Query Messages
The Query Messages file complements the Queries file by displaying each message associated with a particular query. You can use the Query ID as a key to map between the Queries file and the Query Messages file.
The list of columns in the Query Messages file are as follows:
| Column | Data Type | Description |
|---|---|---|
| STUDYNAME | text | Study Name |
| SITECOUNTRY | text | Study Site Three-Letter Country Abbreviation |
| SITENUM | text | Site Number |
| SUBJID | text | Subject Name |
| QUERYNAME | text | Query Name |
| QUERYID | text | Query ID |
| QUERYMSGSTATUS | text | Query Message Status |
| RESTRICTEDMSG | boolean | Restricted Query Message |
| QUERYMSG | text | Query Message |
| QUERYMSGBY | text | Message Created By |
| QUERYMSGDT | datetime | Query Message Date |
| QUERYTEAM | text | Query Team that created the message |
| ORIGINSYS | text | The system from which the query message originated. |
| ORIGINID | text | The ID of the originating system. |
| ORIGINUSER | text | The user who originated the query message. |
| QUICKACT | boolean | Indicates if the message is a Quick Action (true/false). |
| QUICKACTTYPE | text | The type of Quick Action taken. |
| ROWWRITEDT | datetime | Datetime the row is written to the file |
| ROWID | text | Row ID |
Reference Data Files
The reference data includes files for Labels, Display Override Labels, Deletes, Local Lab Unit Definitions, and Local Lab Codelist Definitions.
See Incremental Extraction for information regarding the DELETES file.
Labels
The Labels file displays labels related to Study Definition objects such as: Event Groups, Events, Forms, Item Groups and Items. The file includes labels from the latest study design version and is only available with the full SFF ZIP package. Labels are displayed in the language set for the vault in use.
The list of columns in the Labels file are as follows:
| Column | Data Type | Description |
|---|---|---|
| NAME | text | Object Name |
| LABEL | text | Object Label |
| TYPE | text | Object Type (such as eventgroup, event, form, itemgroup, item) |
| ROWWRITEDT | datetime | Datetime the row is written to the file |
| ROWID | text | Row ID |
Example of a Labels file:
| NAME | LABEL | TYPE | ROWWRITEDT | ROWID |
|---|---|---|---|---|
| prescreening | PreScreening | eventgroup | 2024-06-01T21:06:00Z | prescreening_eventgroup |
| visit1 | Visit 1 | event | 2024-06-01T21:06:00Z | visit1_event |
| physical_exam | Physical Exam | form | 2024-06-01T21:06:00Z | physical_exam_form |
| ig_prescreen | PreScreening | itemgroup | 2024-06-01T21:06:00Z | ig_prescreen_itemgroup |
| dob | Date of Birth | item | 2024-06-01T21:06:00Z | dob_item |
| in_progress__v | In Progress | event_status | 2024-06-01T21:06:00Z | in_progress__v_event_status |
| submitted__v | Submitted | event_status | 2024-06-01T21:06:00Z | submitted__v_event_status |
| blank__v | Blank | event_status | 2024-06-01T21:06:00Z | blank__v_event_status |
| did_not_occur__v | Did Not Occur | event_status | 2024-06-01T21:06:00Z | did_not_occur__v_event_status |
| planned__v | Planned | event_status | 2024-06-01T21:06:00Z | planned__v_event_status |
The Row ID may be a concatenated string in the above example.
Override Labels
The list of columns in the Override Labels file are as follows:
| Column | Data Type | Description |
|---|---|---|
| SRCDEFINITION | text | Source (Object) Definition Name |
| SRCLABELTYPE | text | Source (Object) Label Type: such as an eventgroup |
| TARGETDEFINITION | text | Target (Object) Definition Name |
| TARGETLABELTYPE | text | Target (Object) Label Type: such as an event |
| TARGETOVERRIDELABEL | text | Target (Object) Override Label |
| SOURCE | text | Data source |
| ROWWRITEDT | datetime | Datetime the row is written to the file |
| ROWID | text | Row ID |
Local Lab Units
The Local Lab Units file displays the Unit Definitions related to the Local Labs module.
The list of columns in the Lab Units file are as follows:
| Column | Data Type | Description |
|---|---|---|
| UNITNAME | text | Unit Definition Name |
| UNITEXTID | text | Unit Definition External ID |
| UNITTYPE | text | Unit Definition Type |
| UNITITEMCODE | text | Unit Item Definition Code |
| UNITITEMDECODE | text | Unit Item Definition Decode |
| UNITITEMEXTID | text | Unit Item Definition External ID |
| UNITITEMABBR | text | Unit Item Definition Abbreviation |
| UNITITEMSTANDARD | boolean | Unit Item Definition Standard |
| UNITITEMCONV | text | Unit Item Definition Conversion Formula |
| SOURCE | text | Data source |
| ROWWRITEDT | datetime | Datetime the row is written to the file |
| ROWID | text | Row ID |
Local Lab Codelists
The Local Lab Codelists file displays the Codelist Definitions related to the Local Labs module.
The list of columns in the Local Lab Codelists file are as follows:
| Column | Data Type | Description |
|---|---|---|
| CODELISTNAME | text | Codelist Definition Name |
| CODELISTEXTID | text | Codelist Definition External ID |
| CODELISTITEMCODE | text | Codelist Item Definition Code |
| CODELISTITEMDECODE | text | Codelist Item Definition Decode |
| SOURCE | text | Data source |
| ROWWRITEDT | datetime | Datetime the row is written to the file |
| ROWID | text | Row ID |
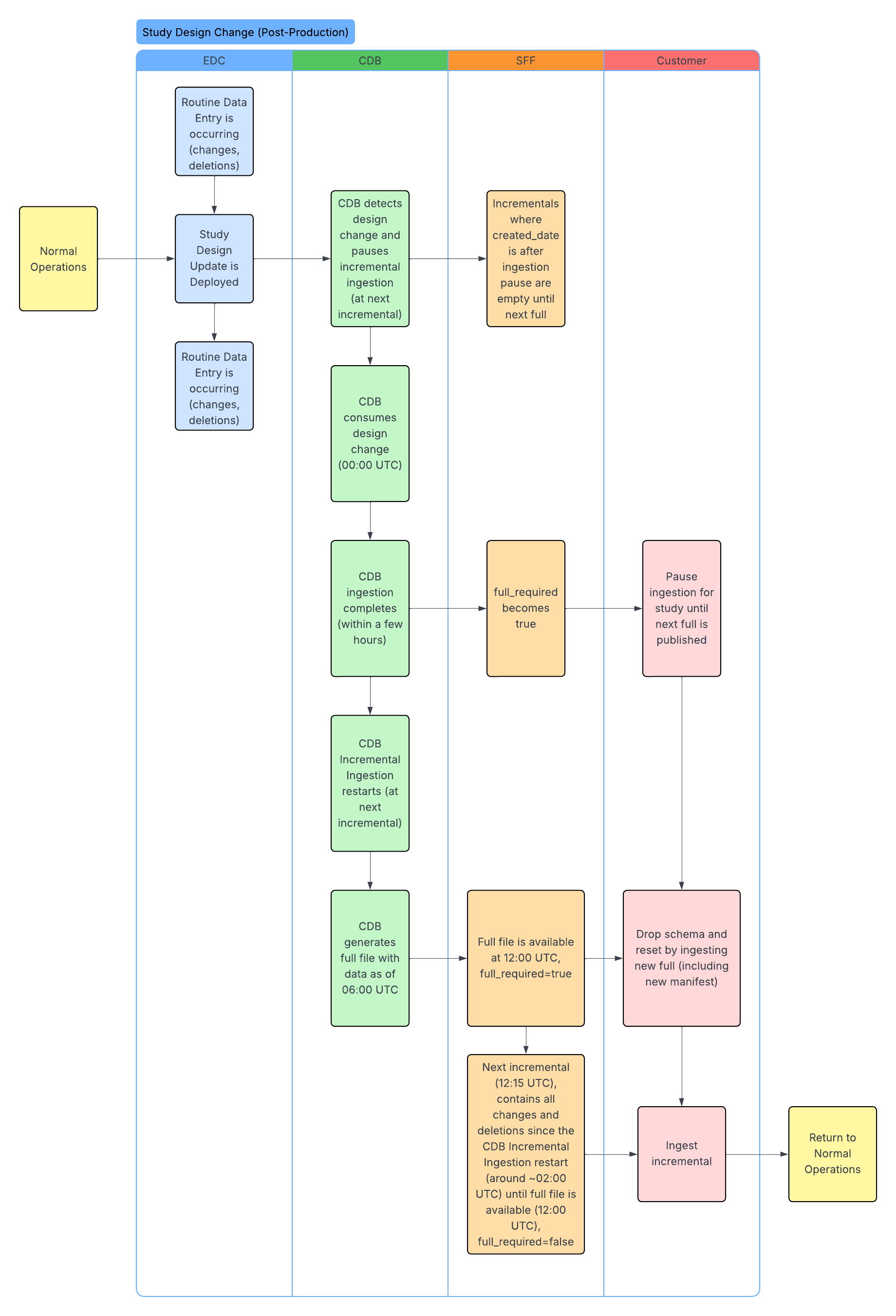
Understanding Study Design Changes
If a study design change occurs in EDC, a new casebook version is published. Once CDB ingests and applies the design changes, the API response returns the full_required field as true for both full and incremental extraction packages. When full_required is true, packages are still produced but they are empty. This happens because packages remain accessible for 48 hours. For example, an empty package can be returned even if the feature is turned off, provided the 48-hour time limit has not been reached.
The API response is interpreted differently depending on whether the extraction is incremental or full:
- For an incremental package, a true response means that incremental changes have stopped, and you have to wait for the next full SFF package to resume updates.
- For the full package, a true response means that the package can be used to refresh your data with the latest full set.
Standard Workflows
The following workflows illustrate the SFF lifecycle, including initial enablement, data ingestion, and how updates occur after study design changes. The CDB column headers below represent the CDB infrastructure. We ingest data through the CDB infrastructure to produce the SFF.
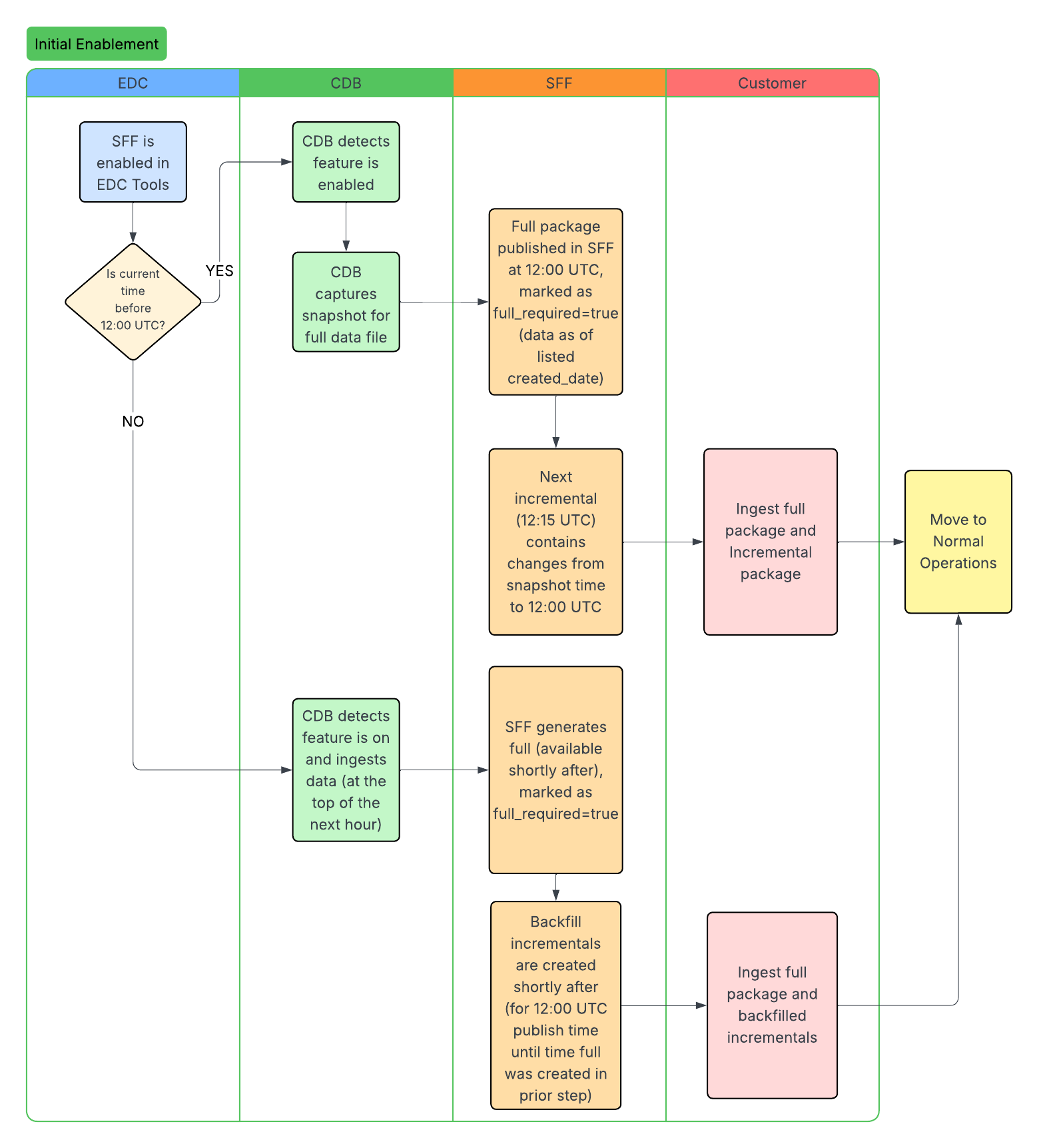
Initial Enablement
Normal Operations
Study Design Changes